The inevitability of Data Lakes
Vendors of traditional Data Warehousing systems are afraid of Data Lakes, and they'd like you to be afraid of the challenge of getting data out of them. However, the traditional data warehousing model, where corporate data is transformed into its final schema for processing as soon as it is collected, is untenable in an age of innovation. If you need to change your data warehouse schema every time you change your applications, you'll either never change your applications or your data warehouse will become obsolete. Yes, we need order to tame the chaos of real-world data, but the best way to do that is to be able to apply order after the fact, to continuously find new uses for the data we already have.
Technical trends leading to Data Lakes: Hardware
Whether or not you care for the word, Data Lakes owe a lot to the idea of the Hyper-converged architecture. Lets take a moment to compare this to the traditional architecture used in high-end enterprise servers in recent years. Data Warehousing and other high-performance servers have frequently depended on Storage Area Networks (SANs)
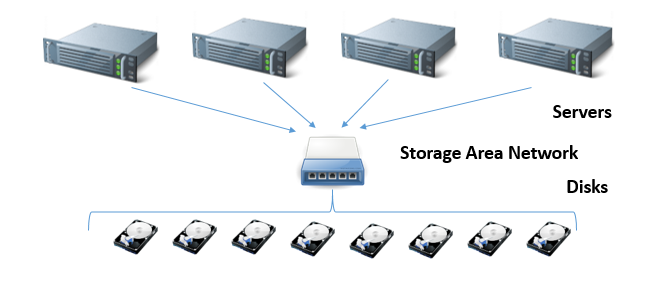
With a SAN, we can connect a large number of disks to the SAN on one end, and we can plug servers on the other end. We can apply RAID protection to the disk array, and then carve the array up into multiple volumes, each of which looks like a very high performing (and possibly very big disk.) If the SAN fabric contains battery-backed RAM, we can report the completion of transactions to the server right away (before a chunk of metal movies to write the data), meaning we get great performance for transactional databases.
The trouble with the SAN architecture, however, is that it does not scale. So long as we depend on a special piece of hardware to pretend that a disk array is just a disk, our performance is limited by that single piece of hardware. If we add more servers and more disks, we will run into increasing costs, performance bottlenecks and additional problems that will bring expansion to a halt.
In the hyperconverged architecture, disks are attached directly to servers, so that the connection between disks scales with the number of servers:
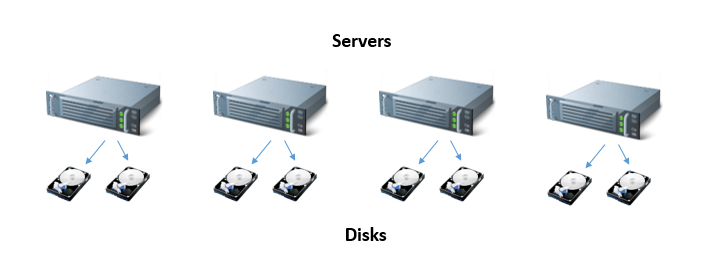
The scalability story is as follows: if you want to enlarge the cluster, add additional servers. Each additional server adds additional disk space, so the ratio between computing power and both disk capacity and disk bandwidth stays constant. There could still be other bottlenecks in the system, but the storage interconnect is not one of them. The trade-off, relative to the storage area network, is that the storage no longer looks like a single disk, so that the content of the disks is not synchronized in time. We can't use the synchronization implied by fsync() to implement ACID transactions and frequently distributed systems implement eventual consistently precisely because the cost of maintaining perfect synchronization and coherence increases with the size of a cluster.
The real benefits of this hardware organization come when you pair it with the right kind of software: in particular, since each storage volume is directly attached to a computer, each computer can do the initial parsing step that extracts facts from the documents it holds without communication with the other cluster members. (This is the "map" phase in the MapReduce programming model.) In most cases, the extracted information is considerably smaller than the original documents, so when we gather together (or accumulate) the results, a much smaller amount of information is sent across the network connection:
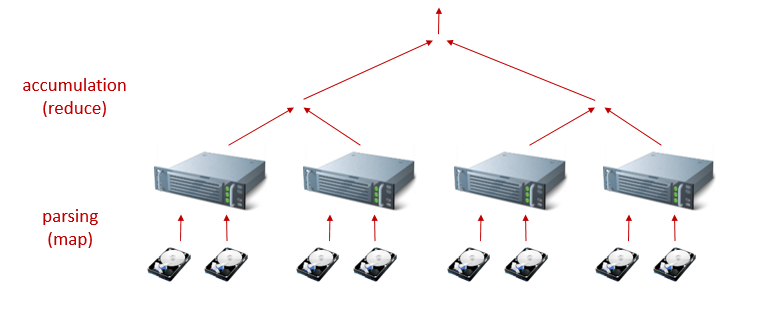
This approach is perfectly suited for Data Lakes, in which we are going for a panoptic view over a large document collection, because of the large computing capability coupled to the storage. Although we can, and should, use a number of mechanisms to reduce duplicated work, hyperconverged systems have the power to scan the complete data set in a reasonable amount of time, which means we can repeat the data analysis at any time to reflect changes in either the code or data.
Data Lakes vs Data Ponds

Data Lake technology can be applied against different kinds of storage systems:
- Conventional file systems: the vast majority of applications do not require particularly "big" data; to take one example, we did a historical analysis of legal entity identifier data. A single copy of the daily file is about 50MB and the storage required to look at all the daily files side by side adds up to about 20GB. Data sets that fit on a single computer face serious velocity, variety and veracity requirements and can benefit from data lake technology. (ex. forensic analysis of a captured computer)
- HDFS, MapR and other distributed file systems: By default, HDFS keeps three complete copies of each data item on three different servers. This gives extreme reliability and also gives the system flexibility to move computations close to the data. In a corporate environment, an ideal implementation is to have a single large Hadoop cluster which is shared by a number of workgroups. In this setup, maximum burst capacity is available for projects when needed. Products such as MapR seek to reduce the overhead of replication, but three-times replication in a hyperconverged environment compares favorably with cost with traditional enterprise storage systems.
- S3, Azure Storage, Swift: MapR and other object storage systems: Cloud storage systems such as S3 are highly scalable, even if they don't locate computing immediately next to storage. Large customers ready to make a large investment can get better performance at a lower price by buiding a corporate cluster, but cloud storage combined with cloud computing can put burst capacity for data lakes into any organization's reach.
Thus, to capture the bulk of the market, a data lake toolset needs to address projects of wildly disparate size. That's what scalability means: it means not just big, but able to function on a long range of scales. People talk of at least five "V"'s of Big data:
- V1: Volume
- V2: Variety
- V3: Velocity
- V4: Veracity
- V5: Value
We need to start with with the end, Value, in mind, but that value won't materialize if we don't address Veracity. Variety can be a serious problem long before a large Volume of data is accumulated. Velocity refers to not just the speed of data processing, but the speed of analysis, software and product development -- these of course are closely related and they support Veracity in allowing you to properly test the system and freeing up developers to think about creating Value. Real Semantics addresses all five V's for data sets of all sizes by applying a limited number of methods and strategies to common problems that appear at all scales.
Design for scalability
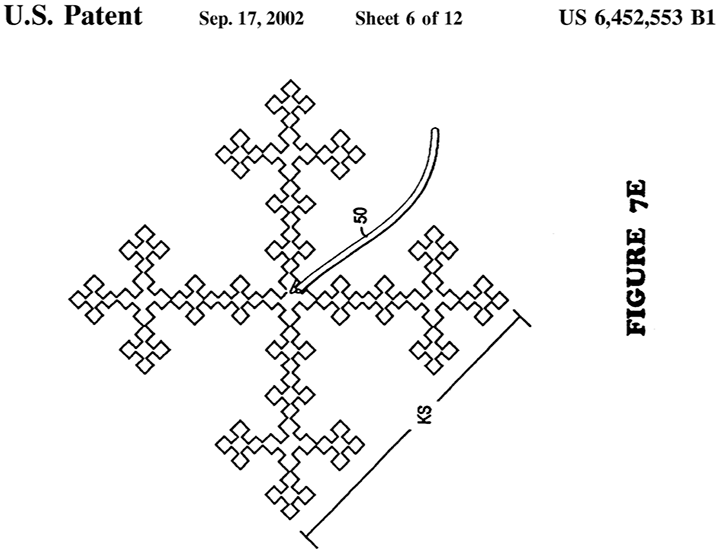
The illustration above is of a fractal antenna, a technology that has taken off in the last 15 years or so outside of the public eye, as they are often hidden on the inside of a cell phone or inside a sealed radome in a digital television antenna. Typically the size of an antenna (or part of an antenna) is on the scale of the wavelength of the radio waves that it interacts with, which is inversely proportional to the frequence. Fractal antennas work at a wide range of frequencies because they contain both large and small structures. This fits the wide frequency range used for television transmissions (54-692 MHz) and the multiple cellular and WiFi bands supported by a modern cellular phone.
In many areas of science, there is a characteristic scale for size, time, mass or some quantity like that. For instance, the atomic nucleus is roughly 1 femtometer (10-15m) in size, and the electron shell of an atom is about 0.1 nanometers (10-10m) in size. Atoms don't vary that much in size: a particularly small atom has a diameter of 0.1 nm and the largest has a diameter of about 0.6 nm. Many real-life quantities vary more than that because of the lack of a natural scale. For instance, you can find human settlements as large as Tokyo (33 million people) and as small as Magdalena, NM (926 people). Many quantities that you find looking at practical data, such as:
- The sizes of files in a large document collection
- The number of emails written by different authors
- The number of times a predicate in an RDF database is used
- The number of times a class is used in an RDF database
- The value of customer accounts
vary over many orders of magnitude and cannot be modelled well with a normal distribution and are better modelled by a log-normal or power-law distribution. "Exceptional event" are the new normal, and as you increase the volume and variety of data you work with, you'll find that extreme distributions can be a source of bottlenecks and will need to work around them.
Real Semantics has a fractal structure because it is designed to reuse the same data structures at multiple scales. In particular, Real Semantics represents everything as RDF graphs, RDF datasets, or RDF result sets. We can store a small RDF graph in an in-memory Jena Model, a structure that can be used much like programmers in a language like PHP, Perl or Javascript would use a hashtable. Large RDF graphs can be stored in a number of open-source and commercial SPARQL databases such as Blazegraph, OpenLink Virtuoso, and AllegroGrqaph just to name a few. The existence of RDF and SPARQL standards mean you can choose different databases for work in different environments and different scales. In Real Semantics we speak of "data droplets" which are typically small RDF graphs that represent the facts in a particular document, about a particular topic, or relevant to a particular decision. With a common toolbox that can be applied to data of all sizes, Real Semantics can roll with the punches, moving processing from one stage to another to break through bottlenecks and meet changing requirements without constant re-engineering.
We'll look at one more example of fractal architecture to explain the benefits:

Plants are based on fractal principles because fractal designs scale in both space and time. If you were building a house you'd have to finish perhaps 60% of the construction before you can live in it, but a plant captures energy from its very first leaves to grow by factors of thousands, even millions. It's simple for the plant too, because it is encoded in the rules controlled by cell division; armed with just a little information about their local environment, cells can make decisions that produce a complex-appearing shape that is sketched out only in the abstract in the plant's DNA.
For Real Semantics, RDF nodes and RDF triples are like atoms and atomic bonds. We put them together to make molecules and eventually droplets of data. The underlying graph model is universal: we can mirror conventional data structures quite directly with nodes and links between node. We apply semantics, or meaning, to the graph in a layer that is built on top of that basic model. That lets us combine operators that work on graphs as "graphs" together with relational operators, logic, conventional Java code and the kind of transformations used in programming language compilers.
What is a data droplet?
A data droplet is a graph of nodes and relationships concerning a document, topic, situation or decision. Real Semantics uses RDF graphs and datasets to implement data droplets. The JSON-LD specification represents one view of data droplets, although we prefer the Turtle language when we write droplets by hand.
@prefix : <http://example.com/appliances> .
@prefix dbpedia: <http://dbpedia.org/resource/>
[
a :WashingMachine,:FrontLoadingWashingMachine ;
:capacity 4.8 ;
:supportedVoltages 120, 240 ;
:phases ( "Soak" "Wash" "Rinse" "Spin" ) ;
:energyCostEstimate
[
:source dbpedia:United_States_Environmental_Protection_Agency ;
:hotWaterSource "electric" ;
:annualEstimatedCost 16.00
],
[
:source dbpedia:United_States_Environmental_Protection_Agency ;
:hotWaterSource "natural gas" ;
:annualEstimatedCost 14.00
]
]
The above is the kind of droplet you can write right off the cuff. It's a lot like a JSON document in that you can nest groups of properties inside the square braces []. We inserted ordered lists using curved parenthesis (). Nested structures can be build into lists. Some more subtle details are in this example too. We use three different numeric types, including floating point, integer, and decimal. That last one is important: if you use floating point to do financial calculations, you will someday cut somebody a check for the wrong amount. COBOL got it right with mainframes in the 60s, but ordinary JSON lacks a decimal data type. Another feature RDF adds over JSON is data types for times and dates. You'll need to formalize something if you want to exchange times and dates, and you might as well use the standards baked into the XML Schema Data Types.
The ordered lists represented are conceptually the kind of linked lists used in languages like LISP, and in fact you can write LISP S-expressions in Turtle exactly as you would in LISP (except for requiring spaces around the parenthesis and a period at the end):
( <fn:numeric-add> 2 2 ) .
RDF: A New Slant is another chapter in this book that describes another take on Data Droplets. Just like the blind men discussing an elephant, there are many viewpoints that you could approach them with. In the case of Real Semantics, which is written in Java, the problem of moving data from Java objects to and from RDF is the most urgent problem, for several reasons: (i) many libraries for importing and exporting Java already exists, (ii) Real Semantics can most easily use Java language libraries to do things that it wants to do, such as launch cloud servers, read file metadata and initialize objects with Spring, and (iii) developers can extend Real Semantics by writing Java code.
The Java to RDF mapping in Real Semantics is a bit deeper than many data mappings that you see in other frameworks such as object-relational mapping. It is best compared to the meta-object facility promoted by the OMG in that it addresses three basic requirements:
- getting a property from an object
- setting a property from an object
- calling a method on an object
The first two of these are common in tools such as rdfBean, JAXB, Hibernate, Jackson as well as the many imitators of those frameworks you will see with other languages. The third one is a bit less less common, but it unlocks doors that the others do not. Often it looks like we are calling a function (static method) instead of an actual instance method, but it lets us write configuration and code in the RDF world that use the billions of classes in the Java world to specify what needs to be done.
If you were developing a framework like Real Semantics in some other language, let's say Python, Ruby or Go, you'd make different decisions and you would center them around the reality of your language. For instance, we make the most of static typing in Java: we see Java class definitions as an ontology that we can access through the Java reflection API. Together with rules that describe the Java Bean conventions and other common patterns, in most cases we can build a Java-to-RDF mapping without human input. We use this to describe not only data in the conventional sense, but also the configuration that makes Real Semantics go.
JSON-LD defines a relation between data droplets and JSON. Relational tables (and the equivalent CSV file) as well as XML data also translate directly to data droplets. Real Semantics avoids the "impedance mismatch" that is painful in object-relational systems because a 1-1 mapping exists between an RDF graph and traditional data structures. Any reconcilliation between other data models can be done in the RDF world where we have the widest range of strategies on call to address semantic gaps.
We will talk a bit more about the relationship with relational data and XML in another chapter, but for a moment we'll take the idea of data droplets and graph models to their logical conclusion. We've got to be careful in what we say here, because the biggest marketing problem we have with Real Semantics is that people have heard more than 40 years of hype in the Artificial Intelligence and now Machine Learning space have made people deeply skeptical. Yet, the reality is that RDF can represent the kind of tree and graph structures that are useful in capturing the structure and content of natural langugage to a fine degree of granularity.
We do not claim, like Cyc to have a fleshed-out vocabulary for representing 100% of the knowledge in natural language documents, nor do we claim to have an automated system to map natural language text into that representation. What we do claim is that there is a toolbox of modelling methods, such as the Situation calculus, that can be used together to capture critical knowledge from high-value documents, particularly specifications and standards. At this point in time, the construction of such a knowledge base can be at most partially automated -- this functionality would need to be built out based on the needs of a particular application, but the data structure choices in Real Semantics do not pose any obstacle to such development.
Data Droplets: the big picture
The neat thing about data droplets is that they let us think about all data the same way at all different scales. If we zoom in close on a droplet, we see it is a graph in which facts are represented as links between nodes:
If we consider a single document or data record, we can think of that is a single droplet: for instance, individual order records and product descriptions are each represented by a small droplet, or graph. It's possible, and quite useful, to simply copy all of the little graphs to create one really big graph:

That really big graph, the composite graph, could be stored in a triple store or another graph database. Once you've got data loaded into that kind of a database, you can ask arbitrarily complex questions with a query language like SPARQL. Most databases that are so highly flexible, however, aren't all that scalable. Many of them, for instance, keep all of the data in RAM or, despite using disk drives, perform best when most of the data fits in RAM as a cache.
The good news is that the composite graph in the diagram is a conceptual thing, not a physical thing. It gives us (and our software) a clear picture of what the facts look like if we put them together. Real Semantics can materialize this graph in a graph database, but it can also use a scalable fabric to take the input droplets apart and reassemble them in desired form. The point is not that every component used by Real Semantics is scalable, but that we can pick and choose between components that work at various scales, knowing we can use highly expressive algorithms on individual "droplets" while using the most scalable methods to assemble the droplets required to understand a situation or make a decision.
A Document-centric view of computing
One angle on data lakes is that they are centered around documents rather than individual data items one would see in a data warehouse. Our definition of document is very general, as you're about to see, and it leads to an opinionated view about computing in business. That is, just about everything that happens in commercial computing can be thought of as an exchange of documents. This relates to the paper processes that people used before computers came along (we send an "invoice") and to enterprise integration models such as the message queue, as well as communication through protocols like REST and SOAP where the client creates a document, sends it to the server, and gets a document in reply.
It's natural, thus, that we look at the "data exhaust" from an IT systems as a collection of documents (in a batch or "data lake" mode) but that we could also look at happenings in an IT system as a continuous stream of documents passing by in real time which a system can monitor or control.
What is a document?

Our definition of document comprises both human readable and machine readable documents. Thus we'd include plain text, HTML, PDF and Microsoft Word documents on one hand, as well as FIX messages, server logs, database records, and everything in between.
Any computer file at all can be seen as a document which has a name, a timestamp, a size, and probably other attributes such as a creator, access permissions, etc. Working from a semantic web viewpoint where properties come first and classes come later, we could say that the "document nature" of a file derives from it having some basic metadata properties.
Look closely at documents, however, and you find that many of them are composite. For instance, email messages could be archived in an mbox file, but the document itself is a collection of email messages, each of which is a document. Email messages can also contain attachments, thus an email message can itself contain multiple documents.
It's not unusual for an XML document to contain multiple documents, or at least to think of an XML document this way. For instance, every day the Global Legal Entity Identifier Foundation publishes a daily concatenated file. The bulk of this file is a collection of individual records that were supplied by a number of local operating units. A typical record (subdocument) looks like this:
<lei:LEIRecord>
<lei:LEI>2AUNKA7U2OWMOMXRM797</lei:LEI>
<lei:Entity>
<lei:LegalName>Romulus TMK</lei:LegalName>
<lei:LegalAddress>
<lei:Line1>C/O EP Consulting Services</lei:Line1>
<lei:Line2>1-2-9 Nishi-Shimbashi</lei:Line2>
<lei:City>Minato ku</lei:City>
<lei:Country>JP</lei:Country>
<lei:PostalCode>105-0003</lei:PostalCode>
</lei:LegalAddress>
<lei:HeadquartersAddress>
<lei:Line1>C/O Fortress Real Estate (Asia) GK</lei:Line1>
<lei:Line2>29th Floor</lei:Line2>
<lei:Line3>Roppongi Hills Mori Tower</lei:Line3>
<lei:Line4>6-10-1 Roppongi</lei:Line4>
<lei:City>Minato ku</lei:City>
<lei:Country>JP</lei:Country>
<lei:PostalCode>106-6129</lei:PostalCode>
</lei:HeadquartersAddress>
<lei:LegalForm>TOKUTEI MOKUTEKI KAISHA</lei:LegalForm>
<lei:EntityStatus>ACTIVE</lei:EntityStatus>
</lei:Entity>
<lei:Registration>
<lei:InitialRegistrationDate>2012-11-21T15:04:51.576Z</lei:InitialRegistrationDate>
<lei:LastUpdateDate>2015-11-26T02:02:17.524Z</lei:LastUpdateDate>
<lei:RegistrationStatus>ISSUED</lei:RegistrationStatus>
<lei:NextRenewalDate>2016-11-22T14:26:24.426Z</lei:NextRenewalDate>
<lei:ManagingLOU>EVK05KS7XY1DEII3R011</lei:ManagingLOU>
<lei:ValidationSources>ENTITY_SUPPLIED_ONLY</lei:ValidationSources>
</lei:Registration>
</lei:LEIRecord>
A good way to think about it is that the <lei:LEIRecord> is a representation of an actual paper document: a business registration record issued by some government authority. (We've written much more about the LEI demo in another chapter.)
Composite documents, however, turn out to be more ubiquious than one might think. For instance, frequently people bundle a large number of files into an archive file like a tar or ZIP file. The exact metadata held in archive files depends on the format, but generally these are reflective of the metadata you would find in a typical filesystem. What you may or may not know, is that many kinds of popular file formats (such as Microsoft Office document files) are ZIP files in disguise. To demonstrate, I changed the extension of a .pptx file to .zip so that the operating system would treat it as a ZIP file and I clicked on it to see the top level directory:
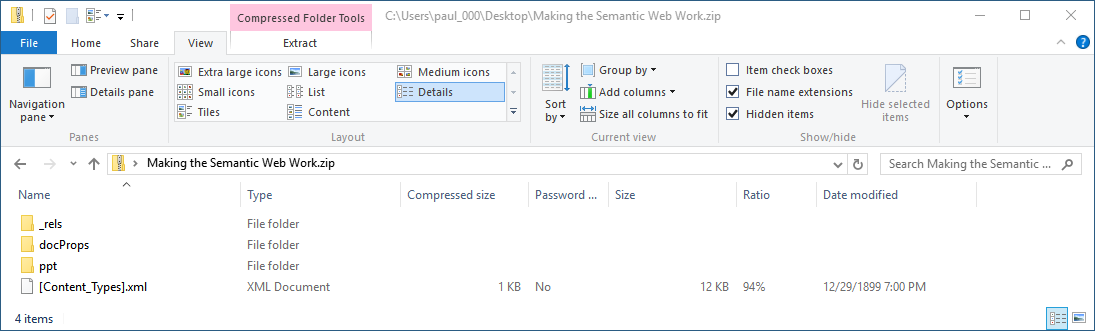
then clicked on ppt
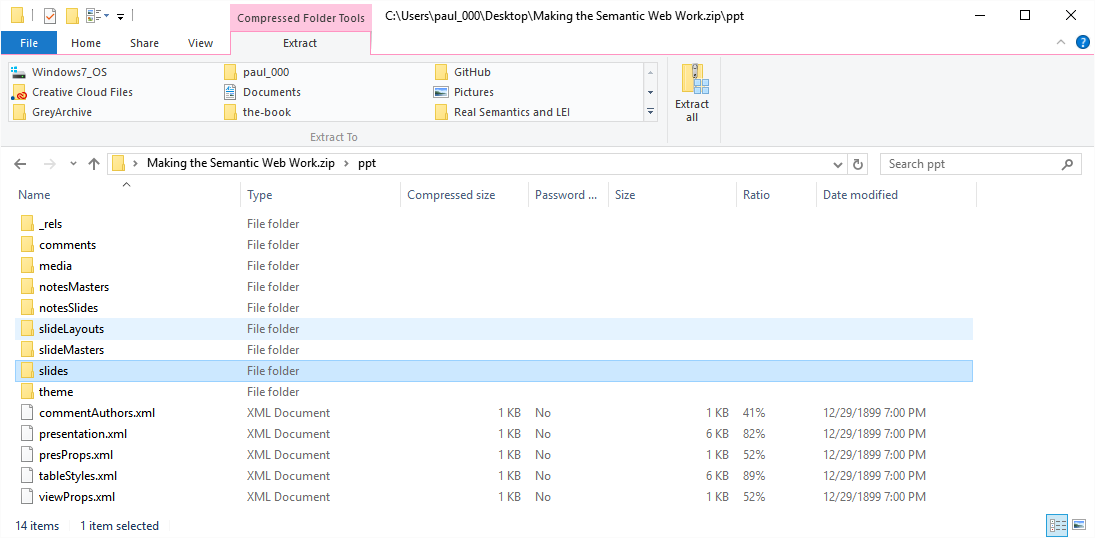
and then on media to see images embedded in the document
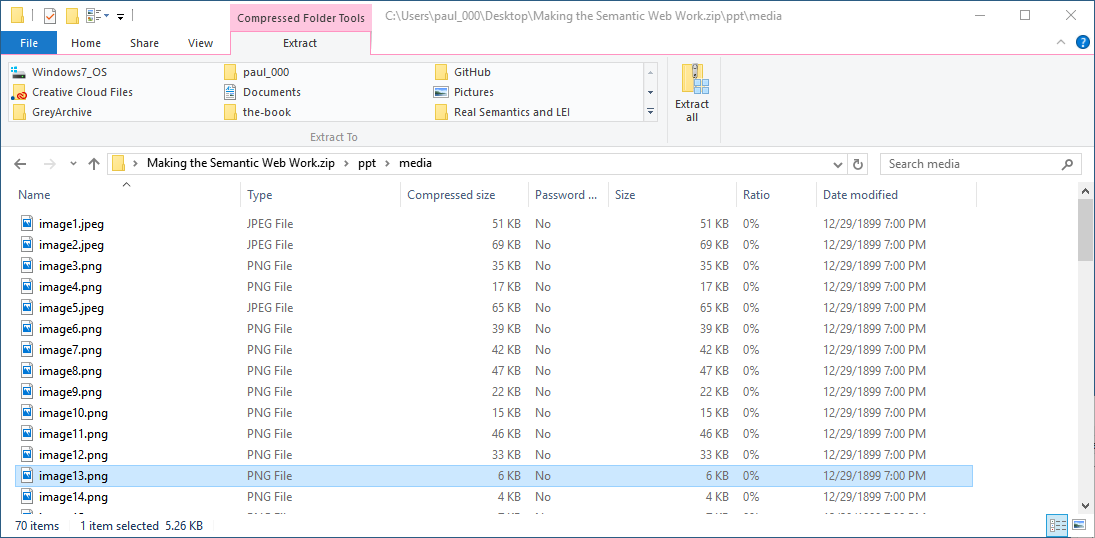
Look in the slides directory and you will individual XML files for the slides. The reality, then, is that you can get a lot out of an office file by treating it as a ZIP even if you don't understand the Office Open XML format; the competing Open Document Format, also standardized by the ISO, similarly represents composite documents as ZIP. (Microsoft has been thinking this way for a long time: before embracing ZIP, Office documents were based on OLE, which provided a systematic (if Windows-centric) approach to working with composite documents.) Java JAR files, of course, also depend on the ZIP format; with a flexible data model that enables reuse, therefore, we can use the capability to look into ZIP files to look into many of the files that play a critical role in Real Semantics and the data lakes that it works on -- demonstrating that by reusing the same components and principles as much as possible, we get a powerful system that is simple for people to understand.
Now, how you perceive documents is a choice. Scanning a large collection of files, for instance, you might not initially be interested in the extraction of individual email documents from an mbox file, and in particular, you might not want to spend the resources required to do this scan. How far we go in breaking down documents is a decision that is up to the user of Real Semantics and is driven by your needs.
Document Metadata as a Document
The XMP standard is the primary inspiration for metadata in Real Semantics because it gets the following things right:
- XMP provides a common metadata format for documents of all kind, implementing general purpose properties (such as Title and Creator) for properties any document can have, as well as properties specific to certain document types such as image and sound files
- XMP builds upon Dublin Core, EXIF and IPTC standards, benefitting from the work done on them
- Possibly uniquely for an RDF-based format, XMP fixes critical deficiencies in the Dublin Core standard. In particular, the Dublin Core standard does not provide a mechanism for specifying that a document has multiple authors specified in a particular order. Practically, the authors of books and papers care a lot what order their names are listed in, so this is a big problem. XMP makes the argument of
dc:Creator an RDF Container, solving this problem easily.
- XMP makes a clear distinction between the data format and properties that are expressed in that data format, which makes it straightfoward to extend it with new properties, as is done in Astronomy Visualization Metadata
- Best of all an XMP extractor can extract XMP metadata from a document that doesn't have XMP Metadata! The XMP specification defines how an XMP extractor interprets legacy metadata from files that don't contain an XMP Block. (A key feature for success, since it is much easier to put that kind of intelligence in the extractor than it is to get document producers to change their behavior)
There are some things we see see differently from XMP, but these are not major problems:
- The XMP serialization format is based on RDF/XML, which has fallen out of fashion. We're still fine embedding an XMP block using RDF/XML, but if we want to work with XMP metadata outside of a document, we're likely to use Turtle instead.
- XMP metadata is intended to be embedded in a document instead of separated from it. There are good reasons for that, particularly that embedded data will stay up to date with a document as people work on it and won't get separated. In Real Semantics, however, we are interested in indexing metadata to survey the contents of a Data lake, thus, separating metadata from the document is usually the the first thing we do.
- The preferred way of representing ordered lists in Real Semantics is to use RDF Collections instead of RDF Containers, since there it is simple to write RDF Collections in Turtle.
In some applications that use Real Semantics, metadata really is the whole point -- that is, if the end application is to create a search and browsing interface for a document collection, Real Semantics is your ideal framework. In other cases we want to dig deeper into documents to extract some deeper meaning, and metadata is just a means to an end. With lots and lots of files to work with, we need a metadata catalog just so we can find the data we want to work with.
Ths picture illustrates the way we think:
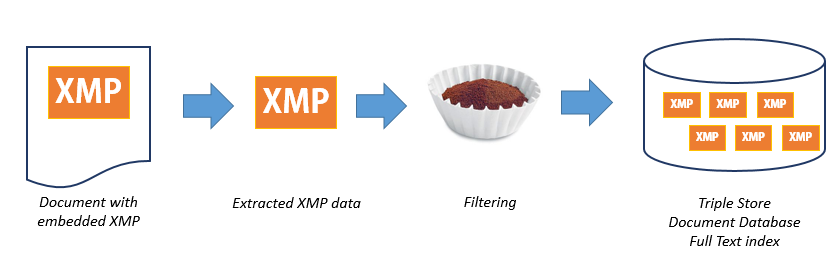
In the case that a document has embedded XMP metadata, we're quite literally extracting an XML document out of the main document, parsing it as RDF, and treating it as a "data droplet". We have all kinds of tools for working on such a document, so we can easily filter, transform, and enrich these documents before we put them in a database of our choice. Scalability isn't just a matter of "keeping your metadata in HBase", but it is also a matter of choosing which metadata you want to store for which objects. The left side of the pipeline above can stay the same, but we can feed the extracted metadata into many different systems on the right side. For instance, we can insert metadata into a graph database, a document database, a full text search engine, or a scalable batch processing framework such as Spark. (Practically it is not so different if there is no existing XMP metadata because we can generate it if it isn't there.)
Secrets of the mogrifier
Conventional programming tools are based on: (i) the idea that execution proceeds from top to bottom in a program and (ii) representing programs as trees, a special form of graph. There is a popular kind of tool, however, that lets users create a program by putting together a graph of "boxes" (functional operations) connected by "lines". This representation is suitable for a graphical representation of a program and you will find in tools such as LabView, Alteryx, KNIME, Actian and Microsoft Azure Machine Learning.
One strength of this graphical representation is that it breaks out of the assumption that a program executes in some specific order. This means a dataflow program can be frequently be parallelized by doing different parts of the calculation simultaneously. Commercial batch workloads frequently benefit from this more than scientific and gaming workloads, because commercial workloads are frequently a sprawling collection of reports that aren't strong coupled to each other, as opposed to scientific simulations that occur as a series of time steps, the beginning and end of which must be synchronized in time. Real Semantics takes advantage of parallelism between job steps, as well as parallelism inside job steps that can be found by processing multiple data records in the same stream at once. And it does all this without the creator of the job understanding parallel programming, meaning that (i) human job creators have an easy job, and (ii) jobs can be created automatically.
We call the part of Real Semantics that executes dataflow programs the mogrifier, a name derived from the Transmogrifier introduced in the Calvin and Hobbes comic strip. For purposes of illustration, here simplified version of the mogrifier job which creates the LEI demo web site:
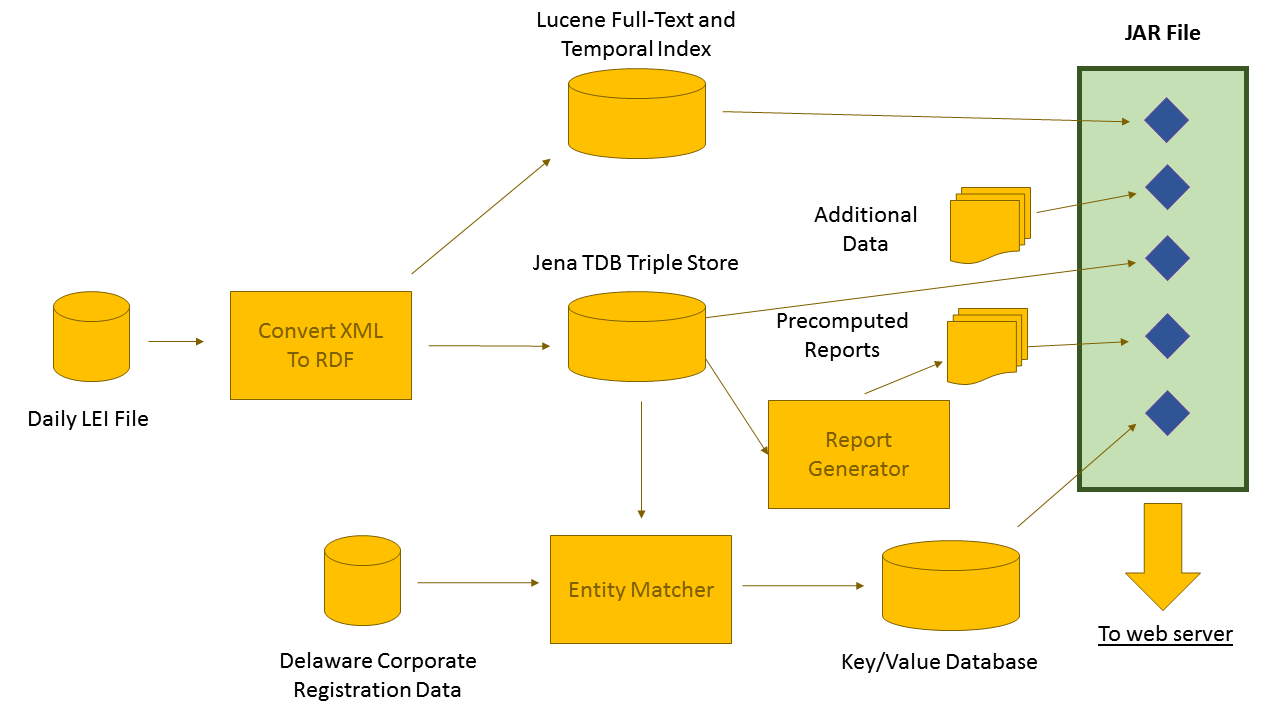
This example is explained in more detail in the LEI demo case study, but we'll just point out a few key features
- The mogrifier lets you specify a computation job at a much higher level than MapReduce, Spark or conventional programming languages such as Python or Java
- In most dataflow tools, the data structure passed along the lines that connect the boxes is a relational row. In the mogrifier, the basic data structure is an RDF graph, or, as we call it, a data droplet, which has many consequences:
- The mogrifier works naturally with NoSQL document-oriented databases
- Data droplets make operations that combine multiple sources of data intuitive. For instance, we could merge a customer's order history together with other information about that customer into a single droplet and feed this information into an inference or machine learning module. Conventional dataflow tools would require the manual creation of "joins" with the consequence that seemingly small changes in the intention can cause the job to change in ways that could make it almost unrecognizable.
- Data droplets let us reuse facilities for data validation and normalization across a wide range of differenct sources
- Data droplets can represent the kind of data structures used by programming compilers; a mogrifier job description is an RDF graph which can be itself processed by the mogrifier. Thus we can automatically generate mogrifier jobs based on rules, schemas and templates.
- The mogrifier is oriented to tasks that will be repeated over time: rather than a data analyst producing a single report interactively, an analyst will work with the mogrifier to produce a report which is, from day one, designed to be repeatable and produce results that can used elsewhere in the business.
Schemas, Ontologies, Theories, and Generic Databases
The mogrifier addresses the low-level aspects of processing information, but there is a lot more to quickly interpreting and working with data in real life. Just as descriptive metadata plays a role in inventorying the data available, and structural metadata breaks documents down into parts, but other kinds of knowledge are necessary for understanding data.
Schemas and Ontologies
Real Semantics recognizes that there is never going to be one standard for writing schemas or ontologies; rather, the best we can do is interpret the information in a number of real world schema languages, often in ways that go beyond what what was originally intended. As you might imagine from what you've read so far, we try as much as possible to use the same tools to work on schemas that we do with other data.
Just to be clear about what we're talking about, I'd say that schema, ontology and "data definition" are roughly equivalent. In all cases, a number of types of entity are defined, as well as properties that those entities have, and typically relationships between entities. A taxonomy, on the other hand, is a classification of entities, and is not centered around the definition of properties that those entities has. (Taxonomies can be hierarchical, such as the classification of living things, but taxonomies can also contain categories that don't fit into a hierarchy, such as "Rear Wheel Drive Cars", and "Cars Made in Europe".) Practically we can incorporate taxonomies, as well as dictionaries and similar knowledge bases, into the system's model of the data that it works on.
Here are a few major purposes for schemas:
- Documentation -- schemas frequently provide human readable information about what data items mean; this may be the most important and most universal us of schemas. Insofar as one thinks of a Java class as a data definition, Javadoc properties are a form of documentation that Real Semantics can extract.
- Specification of data layout -- in languages like SQL and Java, data definitions specify how and where data is laid out in a record. This can promote efficiency. For instance, instead of specifying:
[] :red 134; :blue 175; :green 205 . embedding the property names in the record, you could write the bytes 134,175,205 and let the property be determined by the position. Systems like this lose flexibility, however, since any change in the data definition changes the physical content of the records.
- Validation -- a schema can specify the distinction between valid and invalid data records. For instance, the primary purpose of XML Schema is to define an XML format by applying constraints to the set of all XML documents.
- Inference -- schemas can also contain information that adds to the meaning of a document. For instance, the basic XML specification does not specify types such as dates, booleans, and integers. XML Schema adds type information that changes (or at least specifies) the meaning of the document. XML Schema also supports default values, another kind of inference. RDFS and OWL support another kind of inference, for instance, inferring that a
:Singer is also a :Musician or that the subject of a property :appearsInFilm is always a :Film, even if this is not specified directly.
- Code generation -- think of this as documentation for machines. With the K-Schema used in Real Semantics we generate Java stub classes that define methods and properties. It is possible to generate data definitions in languages like Java as well as to synthesize algorithms, to transform data from one format to another, for instance.
The basic schema format in Real Semantics is the K-Schema, which is designed to represent legacy data structures (such as relational, XML Schema, object-oriented) in RDF. Superficially, K-Schema looks like RDFS or OWL, but it has some crucial differences -- for instance, instead of focusing on the kind of inference that RDFS and OWL do, K-Schema supports validation and default values. In many cases, K-Schema relates to existing schemas in a straightforward way: for instance, if RDFS predicates are replaced with corresponding K-Schema predicates, and we declare the namespaces used in the RDFS schema as being "closed", the resulting K-Schema will validate RDFS properties much like people would expect. K-Schema consists of a simple core, beginning with K-Schema Level 0; core properties represent almost everything commonly seen in schema languages and data definitions: additional properties can be added to the vocabulary to express additional features and constraints.
Theories
Some kinds of data interpretation require algorithms and heuristics that can't be expressed with schemas and ontologies, at least as we know them. Thus,
Real Semantics applies theories, which are software packages that solve common problems. Here are a few examples of theories:
- Even though XML Schema and RDF use standardized ISO dates, common data files use a wide range of date formats that range from "January 7, 1985" to '711120' and even 'last Thursday'. Tools like natty recognize a wide range of common formats, eliminating a huge pain point in data ingestion
- A wide range of different terms such as "Yes/No", "True/False", "1/0" are used to represent boolean values and similar a number of values such as "NONE" or "N.A." are used to represent cases where a data value is not available. Automatic recognition of such cases is another acceleration of data ingestion that cannot be left on the table.
- Given the terms of a financial contract written in machine-readable form, a theory could assign a value and/or risk metrics to a contract, see ACTUS
- In real-world data we might find distances represented with inches or meters, or temperatures measured in Centigrade or Fahrenheit. In some systems (say Mathematica or the HP 48 Calculator) there is a numeric datatype that associates a unit with each number value. More commonly, a system has a convention that certain data properties are represented with particular units. Either way, unit conversion built into the framework is another useful theory and is essential for integration of data from a wide range of sources
- Converting a mailing address to geographical coordinates is a good example of a theory: generally applicable, and requiring a combination of code and data.
- Fuzzy matching of businesses based on name, location, and other information is another example of a theory.
The key attributes of a theory is that it is a bundle of code and date that performs a complex task. The inputs and outputs of a theory conform to an ontology, but a theory has the ability to make calculations and take actions within a particular domain. Theories can be implemented in Java code or with rules, but are ultimately encapsulated into mogrifier jobs either as functional blocks or templates that weave functional blocks into a job.
Generic Databases
It's long been recognized that intelligent systems need a large knowledge base about "common sense" topics in order to perform common tasks such as language analysis. The most famous past effort was Doug Lenat's Cyc project, which integrated roughly 3 million facts into a reasoning engine that can do logical tasks such as "prove that a donut can't talk". More recently, however, we've seem the rise of what we call generic databases such as DBpedia, Freebase and Wikidata which comprise hundreds of millions of facts but have less sophisticated semantics than Cyc.
Real semantics grew out of our experience with generic databases (read about the history) so it is designed to handle these demanding data sets. Challenges here include not only size and complexity, but the fact that specific applications have specific requirements for quality and coverage. For instance, a petroleum company might not be concerned with where Boston or Mount Everest are, but it would be concerned where its wells are. For many applications, however, public data bases are useful for the enrichment and interpretation of private data, here are a few example cases.
- We process data from Freebase to create the Ontology2 Spatial Hierarchy, which is used to locate businesses to geographical regions in the LEI demo. In this case we extracted roughly 10 million facts, and then patched the database to add (or remove) fewer than 100 facts to resolve a high fraction of locations correctly.
- Freebase, DBpedia and Wikidata can be used to rapidly create knowledge bases about topics such as "Hip-Hop Musicians", "Inorganic Chemicals", and "Ski Areas". When applied to a particular use, errors and omissions will be discovered, but by avoiding the "blank page" problem, we can get a faster and frequently better result than if we started constructing such a knowledge base manually
- Generic databases are particularly useful for identifying common terms that occur in unstructured, natural language documents and doubly useful for multilingual applications where frequently translations for named entities can be obtained rapidly for free
Ontology2 experience with generic databases, together with data quality and transformation tools and the unique Fact Patch mechanism means that you can import data from generic databases and other public data sources but apply your own corrections in cases where the underlying data source is either outright wrong or just splits hairs differently than you do.
Conclusion: Data Supply Chain Management
If I had to give you one explanation of why Linked Data hasn't changed the world just yet, it is that (i) quality is in the eye of the user, and (ii) there is no feedback loop that connects the success of the end user to the success of the publisher. Often a Linked Data (or any public data project) has a predetermined budget and schedule, so that the publishers don't benefit from doing a better job. Somebody frustrated with the non-profit sector might think commercial values could help, i.e., if publishing "good" data meant the difference between starving in the dark or driving a Ferrari Testarossa to work, things might get better.
Experience shows that even the best commercial organization can do shoddy work. More fundamentally, quality is in the eye of the beholder, and searches for the "meaning" of quality that transcend it's subjective nature have a way of descending into madness. Follow the mailing list for products like DBpedia, Freebase, or Wikipedia and you'll find a number of "voices in the wildnerness" complaining that these products don't meet some definition of quality that they desire, or require for something they are doing. At best these projects have a defined mission, such as DBpedia extracting facts from Wikipedia, or Wikidata serving certain needs of the Wikipedia projects. A flip side, however, is that "Data Wiki" projects such as Wikipedia and Freebase struggle to get meaningful contributions from a community, because the people who have something to contribute are people who have their own viewpoint of quality. Fix quality problems for yourself and you have them fixed. Fix quality problems for the community and you'll have to fight with the administrators and everyone else who thinks you either split hairs too much or split the wrong hairs.
The problem turns up in general when you depend on upstream data sources:
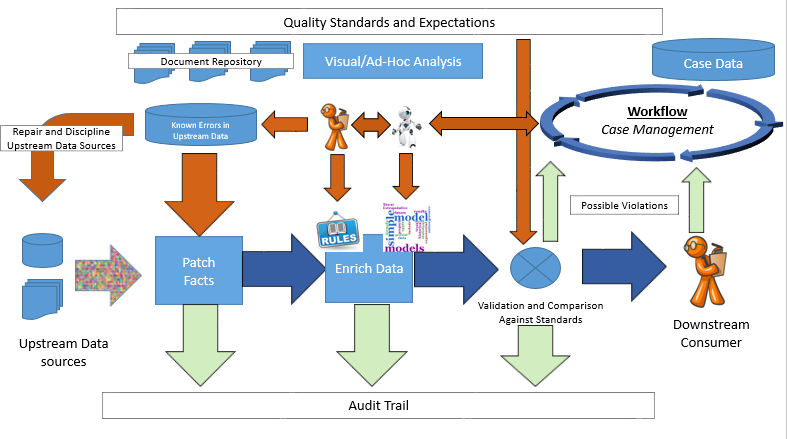
A specific example I'd bring up is the Global Legal Entity Identifier System; although the GLEIF system has a challenge procedure that lets you get one-off errors fixed at the source, data in a global reference database will inevitably be limited and shaped by widely different ideas about transparency and privacy in different legal jurisdiction. Reference data users will always have requirements that exceed what they can get from suppliers, so they need the capability to correct errors in the sources when they can, enrich and correct data for themselves when they cannot, and the wisdom to know the difference. (Apologies to Reinhold Niebuhr)
If have tough requirements for your data, you can't count on upstream sources getting everything right. Real Semantics is about crossing the chasm to semantic application, which means systematically overcoming the barriers to quality this is "good enough" for real applications. The key to this from a process point of view is a combination of the quality best practices used in manufacturing and services and as applied to software reconfigured to apply to data and "data-rich" applications that combine data and software with other services.
The diagram above outlines the vision:
- We recognize that incoming data will be incomplete or incorrect from our point of view. Thus we have a fact patch mechanism and a multiple model architecture applied to data definitions that assumes, from day one, that we'll need to "agree to disagree" with other authorities from time to time.
- We combine rule-based methods that express human understanding in machine readable form with statistical, qualitative, machine learning and predictive analytics to enrich data and compare it against quality standards and expectations
- End users (who don't understand how the sausage is made) can express concerns (which may or may not be correct) about the data in a case management system together with concerns identified by automated screening systems. These concerns can be forwarded to whoever is in a position to understand if there is a real problem and how to fix it, document what happened, and add case data to automated tests and machine learning training sets.
- Standards and expectations for the process are stored in a document repository which can be indexed against code, data items, and cases.
From our viewpoint, the all of elements of Real Semantics are necessary if we want to make a serious dent in the difficulty of incorporating data into intelligent systems (see the arguments in "No Silver Bullet".) The Wright Brothers attained flight not just through producing thrust, increasing lift, and reducing drag, but by clearly understanding the problem of controlling motion in three-dimensional space. We believe our combination of elements can make an impact in the economics of "big data", and that's why we've applied for a patent.