Overview
This article is one of a series describing specific applications of the Real Semantics system. In particular, it describes how Real Semantics builds the Ontology2 Edition of Dbpedia 2015-10. In this particular case, we import RDF data directly from DBpedia into a triple store (OpenLink Virtuoso) without transformation. However, the sheer bulk of the data, and the time involved, forces us to use sophisticated automation to produce a quality product. Working together with the AWS Marketplace, we can provide a matched set of code, data and hardware that can have people working with a large RDF data set in just minutes.
We'll start this article by describing one of the challenges of Linked Data: that is, how to publish and consume data when the costs of data processing, storage, and transfer start to become significant. We explain how cloud publishing lets us square that circle, coupling the costs of handling data to the time and place where people need it. We finish off the business case by considering another case where cloud technology changes the economics of computing and can make formerly impossible things possible.
I (Paul Houle) started making cloud data products long before the development Real Semantics, so I talk about the history of those efforts and how they contributed to the design decisions behind henson, the component of Real Semantics that constructs data-rich applications on cloud servers. Although Real Semantics works just fine on an ordinary computer, it is nice to be able to call upon cluster and cloud resources when necessary, and essential to be able to package code and data reliably for deployment to end users. Finally, we discuss the differences between the AWS platform targeted by Real Semantics and alternatives such as Microsoft's Azure and Hyper-V, as well as container-based systems.
Linked Data and it's discontents
Big Data is a popular buzzword, but how many people are actually doing it? I got interested in the semantic web years ago, when I was making the site animalphotos.info; back then I was doing the obvious thing, making a list of animal species, then searching Flickr for pictures of the animals. I had a conversation with a Wikipedia admin, who turned me on to DBpedia. Between DBpedia and Amazon's Mechanical Turk I no longer needed to make a list or look at the photos, but instead I could import photographs with a structured and scalable process.
In this time period, I went from exploiting general purpose RDF data sources such as DBpedia with traditional tools to my current focus, which is using RDF tools to exploit traditional data sources. Still, at Ontology2 we use DBpedia and Freebase to organize and enrich traditional data sources.
People face a number of challenges using Linked Data sources, such as:
- Handling the sheer bulk of the data
- Understanding what data is there
- Making effective queries against the data
- Understanding and mitigating quality problems in the data
If you think these problems are bad for DBpedia, think of how hard it is to get a complete view of what's happening at a large corporation!
Understanding the data that is there is difficult with the "dereferencing" approach where you go to a URL like:
http://dbpedia.org/resource/Linked_Data
and then you get back a result that looks something like:
dbr:Linked_data
a ns6:Concept , yago:CloudStandards , wikidata:Q188451 , dbo:TopicalConcept , yago:Abstraction100002137 ,
yago:Measure100033615 , dbo:Genre , owl:Thing, yago:Standard107260623 , yago:SystemOfMeasurement113577171 ;
rdfs:comment
"Linked data is een digitale methode voor het publiceren ... de techniek van HTTP-URI's en RDF."@nl ,
"O conceito ... explorar a Web de Dados."@pt ,
"In computing, linked data ... can be read automatically by computers."@en ,
"键连资料(又称:关联数据,英文: Linked data)... 但它们存在着关联。"@zh ,
"Le Web des données (Linked Data, en anglais) ... l'information également entre machines. "@fr ,
"In informatica i linked data ... e utilizzare dati provenienti da diverse sorgenti."@it ,
"En informática ... que puede ser leída automáticamente por ordenadores."@es ,
"Linked Data (связанные данные) ... распространять информацию в машиночитаемом виде."@ru ,
"Linked Open Data ... では構造化されたデータ同士をリンクさせることでコンピュータが利用可能な「データのウェブ」の構築を目指している。"@ja ;
rdfs:label "Dati collegati"@it , "鍵連資料"@zh , "Web des données"@fr , "بيانات موصولة"@ar ,
"Linked data"@ru , "Linked data"@nl , "Linked Open Data"@ja , "Linked data"@en , "Linked data"@pt ,
"Datos enlazados"@es ;
dbo:wikiPageExternalLink <http://demo.openlinksw.com/Demo/customers/CustomerID/ALFKI%23this> , ns26:LinkedData ,
<http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3121711/> , <http://knoesis.wright.edu/library/publications/linkedai2010_submission_13.pdf>,
<http://www.edwardcurry.org/publications/freitas_IC_12.pdf> , <http://knoesis.wright.edu/library/publications/iswc10_paper218.pdf> ,
<http://virtuoso.openlinksw.com/white-papers/> , <http://nomisma.org/> , <http://www.semantic-web.at/LOD-TheEssentials.pdf> ,
ns27:the-flap-of-a-butterfly-wing_b26808 , ns25:book , <http://linkeddata.org> ,
<http://www.ahmetsoylu.com/wp-content/uploads/2013/10/soylu_ICAE2012.pdf>, <http://www2008.org/papers/pdf/p1265-bizer.pdf> ,
<http://www.community-of-knowledge.de/beitrag/the-hype-the-hope-and-the-lod2-soeren-auer-engaged-in-the-next-generation-lod/> ,
<http://wifo5-03.informatik.uni-mannheim.de/bizer/pub/LinkedDataTutorial/> , <http://knoesis.org/library/resource.php?id=1718> ,
<http://www.scientificamerican.com/article.cfm?id=berners-lee-linked-data> ,
<http://sites.wiwiss.fu-berlin.de/suhl/bizer/pub/LinkingOpenData.pdf> ;
dbo:wikiPageID 11174052 ;
dbo:wikiPageRevisionID 677967394 ;
dct:subject dbc:Semantic_Web , dbc:Internet_terminology ,
dbc:World_Wide_Web , dbc:Cloud_standards , dbc:Data_management , dbc:Distributed_computing_architecture ,
dbc:Hypermedia ;
owl:sameAs dbpedia-ja:Linked_Open_Data , dbpedia-ko:링크드_데이터 , dbpedia-el:Linked_Data ,
dbpedia-es:Datos_enlazados , dbpedia-it:Dati_collegati , dbpedia-nl:Linked_data , wikidata:Q515701 , dbr:Linked_data ,
dbpedia-pt:Linked_data , dbpedia-fr:Web_des_données , dbpedia-wikidata:Q515701 , <http://rdf.freebase.com/ns/m.02r2kb1> ,
dbpedia-eu:Datu_estekatuak , yago-res:Linked_data ;
prov:wasDerivedFrom <http://en.wikipedia.org/wiki/Linked_data?oldid=677967394> ;
foaf:isPrimaryTopicOf wikipedia-en:Linked_data .
Now this is pretty neat (particularly in that there is a lot of multilingual information), which is invaluable if you are working on global projects such as LEIs) but you are looking at the data through a peephole. You have no idea of what other records exist, what records link to this record, what predicates exist in the database, etc.
A popular response to that is the Public SPARQL Endpoint, which lets you write SPARQL queries against a data set. SPARQL is flexible, and you can write all kinds of exploratory queries. For instance, the following query finds topics that share a large number of predicate-object pairs with dbr:Diamond_Dogs, a David Bowie album:
select ?s (COUNT(*) as ?cnt) {
dbr:Diamond_Dogs ?p ?o .
?s ?p ?o .
} GROUP BY ?s ORDER BY DESC(?cnt) LIMIT 10
and if you run this against the DBpedia Public SPARQL endpoint you get a very nice list of similar topics.
That particular query takes a few seconds to run, but it's easy to write a similar query that consumes more resources such as
select ?s (COUNT(*) as ?cnt) {
dbr:David_Bowie ?p ?o .
?s ?p ?o .
} GROUP BY ?s ORDER BY DESC(?cnt)
if you run that query on the public SPARQL endpoint (please don't), you'll get a much less nice result:
Virtuoso S1T00 Error SR171: Transaction timed out
SPARQL query:
select ?s (COUNT(*) as ?cnt) {
dbr:David_Bowie ?p ?o .
?s ?p ?o .
} GROUP BY ?s ORDER BY DESC(?cnt)
This is not just a problem with SPARQL, it's a problem that affects any API. If an API is simple and only allows you to do a limited number of things, the cost of running that API is predictable, so it can be offered for free or for sale at a specific price per API call. If an API lets you do arbitrarily complex queries, however, the cost of a query can vary by factors of a million or more, so resource limits must be applied.
An alternative to the public SPARQL endpoint is the private SPARQL endpoint. Here you install a triple store on your own computer, load data, and then run your own queries. People who follow this route run into two problems:
- it takes a lot of hardware. You need 16 to 32GB of memory to comfortably work with DBpedia in a triple store. Memory upgrades aren't that expensive today, but most laptop computers have a limited number of memory slots. Other people don't want to tie up their computer for hours with a task that can slow it down, repeat or it
- it takes a lot of time and technical skill; for one thing, many triple stores lack an effective bulk loader. Openlink Virtuoso has a good bulk loader, but it takes effort to configure it for great performance and reliability. It can take several hours to load a large data set, and if mistakes mean you need to repeat the load several times this can be a cumbersome and frustrating process. (Without automation, you might be tempted to use a data set that than perfect to avoid the process of doing a reload to get it right)
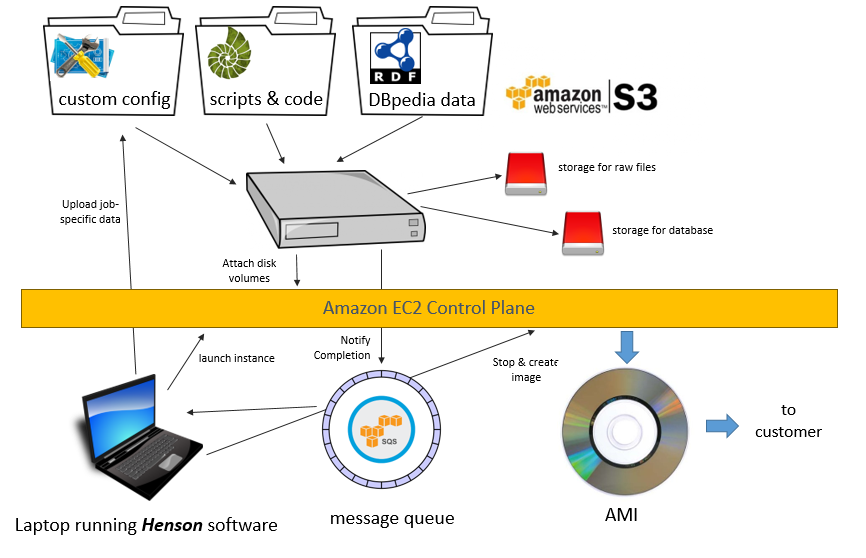
The AWS Marketplace lets us team up with Amazon Web Services to sell you a package of matching hardware, software and data. (See our product, the Ontology2 edition of Dbpedia 2015-10) It is much easier to automate the build process in the cloud, because we always start with an identical cloud server which has a fast connection to the net, as compared to an installer which would need to adapt to whatever the state of your desktop or server is.
Doing things with the cloud that can't be done otherwise

Cloud computing became popular as quickly as it has because it builds upon things we're familiar with. For instance, in Amazon EC2, we're working with servers, disk volumes, virtual networks, and other artifacts that we'd find in any data center. Cloud migration is often a matter of moving applications that are running on real servers onto virtual servers, without a big change in the system architecture.
For ordinary IT applications, the primary benefit of the cloud is simplification of operations. In terms of economics, the capital cost of buying servers is replaced with an hourly rate that is all inclusive. If you're aggressive about lowering costs and keep your servers busy, you can definitely save money with dedicated servers but it's a lot of work. The largest and most margin-sensitive companies like Google and Facebook will run their own infrastructure, but for more and more customers, the convenience of the public cloud wins out.
There is a class of applications, however, that can function only in the cloud. John Schring gave a really great talk about how Respawn Games used Microsoft's Azure to support Titanfall, a groundbreaking multiplayer game. I'm going to summarize what he says here:
Up until that point, online shooter games used a peer-to-peer model, where one of the player's computers would be selected to run a game server. This was necessary because the economics did not work for a game based on dedicated servers. With dedicated servers, a game developer would need to buy racks and racks of servers before the game launches, guessing how many would be needed to support the game. Buy too many and it is a financial disaster, and buy too few, and dissatisfied players will kill the game with bad word of mouth. Although game developers can't predict how many copies of the game will sell or how many people will sell in the first week, it's predictable that the game will be played heavily when it first comes out, and then usage will drop off -- meaning that dedicated servers won't be efficiently utilized.
The peer-to-peer model is limiting, however, because the average gaming PC or game console isn't intended to be a server. For instance, most consumer internet connections are asymmetric, with much more bandwidth available for download rather than upload. A player's computer is busy playing the game, which limits the resources available to the game server. Traditionally, the complexity of the world in a multiplayer game is limited by this -- players might not be aware of how it is limited, but the size of the world and the complexity of interactions in it is sharply constrained.
Titanfall used the Azure cloud in a straightfoward but powerful way. When players joined the game, Respawn's system would launch new game servers in Azure and then tear them down when the game was done. This way, Respawn could put 12 human players (some operating giant robots) in a complex world populated with an even larger number of A.I. characters. Scalability works both ways: Respawn could handle the crush of launch day but still afford to run the game for years afterward with just a trickle of die-hard users, earning loyalty that has gamers waiting for Titanfall 2.
That's the kind of application we want to support with Real Semantics; you don't need a cloud account to use Real Semantics -- you get can work done with Real Semantics on any ordinary laptop or server, but if you ever have a job so big you need a server with 2TB of RAM and 128 CPU cores it is available at the push of a button.