Overview
During the 2008 Financial Crisis, the industry and regulators were in a state of fear and ignorance about the total amount of money owed by derivative markets participants, an amount, on paper, that could have been greater than the U.S. GDP. As a result, the G20 began the process to create a global Legal Entity Identifier which is overseen by the Global Legal Entity Identifier Foundation.
Ontology2 has long been a leader in the commercialization of large-scale semantic databases such as Dbpedia and Freebase. Replacing imprecise names and addresses with specific identifiers is what we do, so we took an interest in the LEI system and started legalentityidentifier.info in August 2014. Our LEI site is what we call an interpretive browser in that it combines a raw information source with additional information, rules and machine learning models to supplement that data with expert commentary.
The legalentityidentifier.info is a product of the Real Semantics framework, both in the sense that it incorporates parts of Real Semantics and in the sense that the Real Semantics framework assembles the software components and data that make up the site. This article, which is part of the Real Semantics documentation, explains the unique attributes of the the legalentityidentifier.info site the relationship it has with Real Semantics. It is aimed at a wide audience, which may or may not be knowledgable about reference data, the financial industry, semantic technology or cloud computing, so we will start with the business case and explain how we apply technology to it.
About Legal Entity Identifiers
A Global Perspective
At this time, the LEI system is driven primarily by the requirements of government regulators. That's a big topic because there are a large number of government regulators in many different countries and jurisdictions. Many of the challenges faced by the system are rooted in the fact that it is international and has to reflect very different conditions in different parts of the world.
For instance, in the United States, there are a large number of federal financial regulators that have different domains. The Securities and Exchange Commission regulates stocks and bonds in the US, while the CFTC regulates options and futures. The FDIC, Federal Reserve Board and Office of the Comptroller of the Currency play a role in the federal regulation of banks, together with the National Credit Union Administration regulating credit unions, as well as the Consumer Financial Protection Bureau and the Federal Financial Institutions Examination Council.
So far as banks and insurance companies are concerned, all 50 states charter and regulate financial institutions as well. All businesses in the U.S. are registered in a state or territory, and the rules of that registration are quite different in different states. For instance, if you form a corporation in New York you need to specify a board of directors (which is a matter of public record) and have an annual meeting which is documented with the state. In nearby Delaware, a single person can register a corporation and nothing about the people involved is in the public record.
Now the U.S. is a large country where states have an unusual amount of autonomy, but you find large variations in regulatory regimes in various countries, particularly when transparency and privacy are concerned. In the UK, for instance, businesses are regulated with Companies House; which makes a large amount of information available on their web site and via an API. Other countries, like the Cayman Islands and Luxembourg, value privacy more than transparency, and publish very limited information, like the state of Delaware. Such "corporation havens" are chosen by registrants on a global free market, but countries that have a different view of the relationship between states and business such as China and Saudi Arabia which see the activities of state-owned enterprises as state secrets.
The result of all this is that the LEI system is a compromise between a number of interests, and largely reflects a "lowest common denominator" of what is available. Relationships between entities (fund/administrator, subsidiary/parent, or branch/master) are an important requirement for risk data aggregation, but these are very much a work of progress because of cross-jurisdictional issues.
Regulatory applications of the LEI
CFTC Swap reporting
The first application of the LEI for regulation was for the CFTC swap reports, which led to the requirement that organizations that trade OTC derivatives in the US register for LEIs. Swaps are financial tools used for many purposes, such as converting a variable interest rate into a fixed interest rate. A major category of swap is the credit default swap, which can be thought of a form of insurance you can buy on a bond. When Lehman Brothers collapsed in 2008, more than $400 billion worth of swap contracts existed on the company, an amount greatly larger than Lehman's debt.
Things turned out to be less dire than expected, however, because most swap market participants held positions that canceled. Swaps are a bit different from stocks and bonds, because you can't just "buy" a swap and them "sell" it the way you would with a stock when you don't like the price. Instead, dealers and traders enter into an position in the opposite direction which cancels out the original position. Once positions were netted out, the amount that changed hands was a relatively modest $7.2 billion. Most swap dealers did a good job of managing risk in their swap books, thus protecting the system, but AIG notoriously sold CDS derivatives without hedging the risk, leading to a $180 billion bailout.
It took quite a while to figure all this out, leading to a large amount of fear and paralysis on the part of the industry, and the CFTC swap reports were introduced to provide clarity in case of a repeat. The idea here is that transactions made at swap execution facility are submitted one of several swap data repositories (SDR.) The data sent to the SDRs uses the LEI to identify the parties to the transaction as well as other entities involved (such as the issuer of bonds insured by a CDS.) SDRs in turn send summary data to the CFTC.The summary data is of limited use because it is not netted (for instance, two parties trading with each other could create a large visible volume without incurring any liability) but in the event of an emergency, regulators can "break the glass" to look at individual trades and positions to get a global view.
EMIR and MiFID II
Today, Europe is taking the lead in the adoption of the LEI. EMIR targeted over-the-counter derivatives and, among other things, developed a swap reporting system similar to that in the U.S. MiFID 2 addresses exchange traded securities and public corporations; it represents a huge advance in reporting standards, introducing both the LEI as a standard identifier and the creation of machine-readable XBRL reports as pionereed in the U.S.
Other applications
These will take time to develop, but in most cases where legal entities interact with the government, the LEI could be a useful identifier. For instance, businesses that contract to provide goods and services with the U.S. government are required to get a proprietary D-U-N-S number. Federal agencies don't have access to the full D-U-N-S database, so this gets in the way of doing analytics about procurement. It has been proposed that the LEI be used as a replacement for D-U-N-S.
A while ago I worked on a search engine for patents and got an insider point of view of the difficulties of that domain. Patents are issued to individuals but are frequently assigned to corporations; if you look at the "asignee" field, however, you find that this field is completely uncontrolled. Our data science team found that there were more than 1000 ways that people wrote "IBM". We were able to match these records with considerable effort, but certainly the results were imperfect. It has been proposed, similarly, that the LEI be used to identify the assignees of patents.
An industry perspective
To fill out the story, the financial industry has it's own motivations to get better control of reference data. The folks at Financial InterGroup call this the "Barcodes of Finance".
The key idea is that behind every trade and customer facing interaction (front office), a bunch of work has to be done to document and finalize the transaction (back office). Historically, and often today, back office work involves manually filled forms with imprecise, natural language names and identifiers. It is necessary to track legal entities, financial products, and trades, and with a sufficiently accurate and fast system shared by all participants, straight-through processing becomes possible.
Straight-through processing has vast benefits, including reduced cost, greater speed and a reduction of clerical errors. The long time involved in international transfers is itself a source of risk. As of mid-2016, there is a large interest in using blockchains to automate payment and trading systems, but whatever the underyling technology is, correct and precise identification of who is participating and what they are trading is essential to any improvement or reform. So long as the LEI as seen as an imposition that comes from regulators, the quality of data is always going to be the least that people can get away with -- thus, meeting industry needs is the direct path to satisfying the needs of regulators. Over the long term we look towards improvements in the LEI system that enable an increasing number of private and public applications.
The architecture of the Legal Entity Identifier System

The architecture of the LEI system reflects the political structure, in that businesses register with one of approximately 30 Local Operating Units (LOU). Every day, each LOU publishes a new data file that lists the entities registered with them, and the GLEIF concatenates these into an official file. Every day, we download this file and rebuild the site. Because the GLEIF permanently retains each data file, we can do a bitemporal analysis that reveals both changes in the data over time (such as companies transitioning between different states) and transient errors that sneak into a daily file and that are quickly fixed.
The GLEIF checks that data from the LOUs validates against an XML schema but does little beyond that to check the validity, correctness, or completeness of the data. Current official data quality reports data quality reports report that LEI data has a high rate of conformance (upwards of 98%) at what they call "maturity level one" but do not address deeper issues. (For instance, more than 20% of LEI records are in the LAPSED state because they have not been renewed by their registrants.)
The legalentityidentifier.info demonstrates how quality improvement can be done from outside the system. Free from politics, we can call attention to issues that the GLEIF cannot, such as companies that are registered in "corporation hotels" such as the notorious 1209 Orange; a practice that degrades the meaningulness of corporate registration even if it is legal and allowed. Our processes discover data quality problems, both in individual records and the adequate, and we pursue the LEI challenge process to fix defective records at the LOU.
LEIs versus other business databases
Legal Entity Identifier records seem to be a lot like other kinds of business databases, such as the National Provider Identifier or the D-U-N-S number. One difference, however, is that Legal Entity Identifiers are issued for traditional business organizations as well as government organizations (such as the City of Pasadena) as well as investment funds and trusts, such as mutual funds and pension funds.)
One aspect of that is that LEI records intersect poorly with other business listings. D-U-N-S records, for instance, cover more than 250 million business entities but do not list investment funds. This puts a cap on the percentage of LEI records that can be matched against D-U-N-S, so if you want to match a higher percentage of LEI records, you need to also match against a database of security identifiers such as CUSIP or BBGID. On the other hand, relatively few business organizations have an LEI at this time -- an analysis of more than 10,000 queries made against the legalentityidentifier.info site shows that many individuals try to look up their own organization and are often surprised to learn that (i) their business does not have an LEI, and (ii) that their business needs to register to get an LEI.
The Legalentityidentifier.info site and Real Semantics
henson: Realizing the Power of Cloud Computing
Real Semantics includes a module called henson, after the famous puppeteer, which is in charge of creating infrastructure in the cloud. Many older generation semantic frameworks, such as Information Workbench addressed the understanding of IT infrastructure as it exists. With henson, Real Semantics can not only understand IT infrastructure, but it can create IT infrastructure. Unlike other big data frameworks which require a large investment in cluster hardware, Real Semantics can run on any ordinary workstation or server and provision practically unlimited resources in the cloud. The following diagram explains the process by which the site is built:
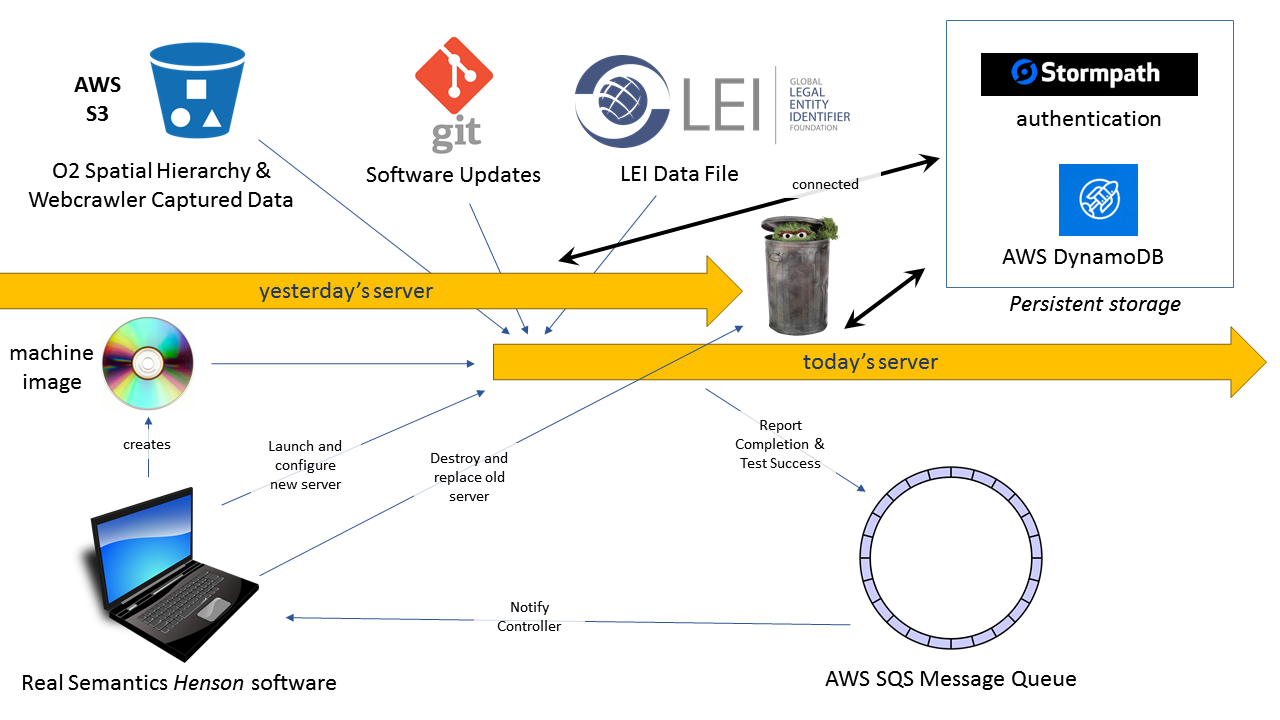
Practically, henson performs two functions with respect to the LEI site:
- Henson creates a machine image that contains the operating system as well as software that the LEI site depends on. This includes installing AWS client software, the Java Runtime Environment, and a number of minor software packages. When possible this is done by using the
apt-get packaging system, but the system is also capable of downloading, compiling and installing open source and other software. This process is typically done once a week.
- Because a new LEI file is released every day, we build a new LEI server every day. Henson launches a new cloud server based on the previously created machine image, and compiles a bash script that runs when the server starts up. This bash script updates the Real Semantics software on the LEI server, and starts a mogrifier job that combines data from a number of sources with a set of software components to create the new site. After the site passes automated integration tests, the new site takes the place of the original server and the old server is destroyed.
This approach has a number of advantages over conventional approaches:
- All software from the operating system on up is refreshed on a regular basis. Software upgrades are not a source of stress, but a largely automated process supported by automated tests and the ability to run servers in parallel until problems are resolved
- In this way we run the latest security patches. In case of a security breach we can create a completely fresh and clean server.
- We can create as many development, test and staging servers to support development and business needs
- Supporting our continuous integration goals, we can test the latest versions of the Real Semantics and LEI site as soon as they are developed. We push changes to the site, user visible or not, almost every day, avoiding risky "big bang" deployments
- With cloud deployment, we've got many options for deployment of the site: for instance, we can make a machine image of the new server and put it behind an Elastic Load Balancer to support arbitrary heavy use. We can run the software on any machine from the
t2.small to the r3.8xlarge with as many as 32 CPU core or operating costs lower than 10 cents per hour.
- The LEI site fits comfortably on a single server, so we locate all services on a single server for the fastest possible speed for end users; just as easily we can build multiple servers and configure them in a cluster
- The LEI site fits comfortably on a single server, so we locate all services on a single server for the fastest possible speed for end users; just as easily we can build multiple servers, distribute services over multiple servers, and deploy a cluster.
- Although the main database for the LEI site is constructed daily, persistent information can be stored in secondary databases apart from the main server. For instance, we use Stormpath for authentication as a service, and Amazon's DynamoDB for information that outlasts an individual server. In either case, Henson configures the server with whatever it needs to connect to outside services.
- Since AWS bills by the hour and it takes about 20 minutes to build a new server, users are completely isolated from the performance impact of building a new server for just a 5% premium in cost. Logging and performance information is sent to Amazon Cloudwatch to gather the results from all servers into a single place.
mogrifier: data-driven data transformation
Henson sets the stage on which the legalentityidentifier.info site is constructed by creating and configuring a server, but the rest of the construction work is done by the mogrifier, another component of Real Semantics.
A modern high-performance application typically contains more than one "database". For instance, although many relational databases and triple stores contain a full-text search engine, typically you get better relevance using a dedicated search engine such as Lucene. If you want autocompletion or typeahead search, you'd do best with a specialized index such as Cleo. Intelligent systems could contain a curated database of facts and rules or a machine learning model involving random forests or neural networks. No matter what, data-rich applications contain raw data, pre-computed results, and specialized indexes that power fast and accurate interactive queries.
The mogrifier starts with a map of the process that transforms raw data into the databases and indexes required to power a product. In the case of the legalentityidentifier.info site, this map looks like this:
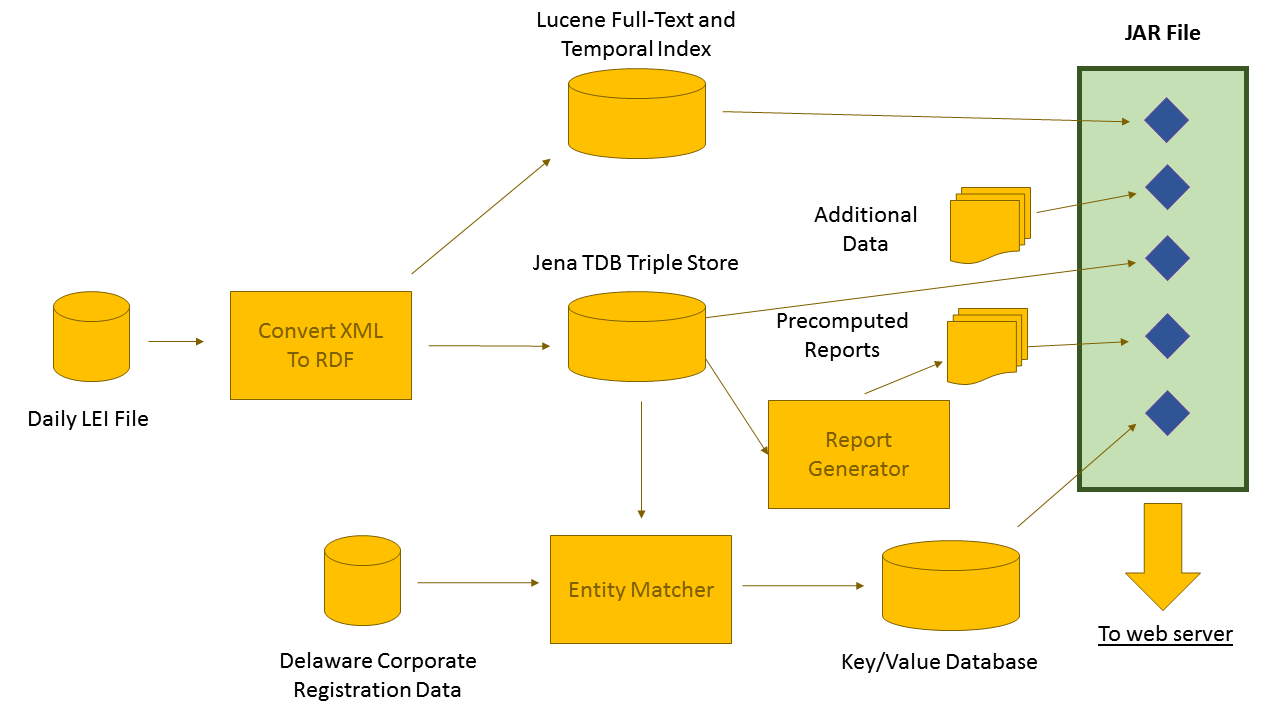
There are quite a few products on the market which can construct a dataflow from a GUI map in this way, such as LabVIEW, Alteryx, and KNIME. Real Semantics does not include a visual editor at this time, but it has a few features that other products do not:
- Most dataflow tools pass individual scalar values (numbers) or relational rows on the lines the connect transforming boxes. The mogrifier passes RDF graphs along the lines -- this highly flexible data structure can carry relational rows as well as nested JSON and XML-style structures. Real Semantics is compatible with the NoSQL data models that are emerging today, and makes it possible to build a 360 degree view of a customer in a single place rather than hiding it behind a complex mess of manually defined join operations.
- The mogrifier can work with both partial and complete graphs. For instance, when data passes from the XML-to-RDF converter to the TDB database and Lucene index, it is broken up into a set of individual graphs, one for each LEI record. Once the data has been completely loaded into the RDF graph, the report generator can run SPARQL queries against the complete dataset.
- The mogrifier supports not only the relational operator based transformations from most boxes and lines tools, but contains more intelligent functional blocks that do functions such as entity matching and the operations performed by programmin language compilers. We're more interested in providing packaged intelligent functions than we are in requiring experts to create them.
- A mogrifier job is itself an RDF graph which the mogrifier can operate on. One advantage of this is that a mogrifier job can add new tasks to itself from running. For instance, if we wanted to generate a report for every country in the world, the mogrifier can query the country list and add reports to the job.
- The mogrifier embeds small artifacts (the things that it creates) into a JAR file and embeds connection information (filenames, ip addresses, usernames, etc.) into said JARs. In the case of the LEI application, these artifacts are discovered by the Spring framework and incorporated into the app.
- Because the job description is a graph, it is possible to stick together two or more job descriptions to make a new one. For instance, the job for the legalentityidentifier.info site produces a very simple Lucene index that indexes only the fields used by the site. We have an additional partial job description, that when added to the main job description, writes a more complete index to Elasticsearch that we browse visually with Kibi. By adding another graph, we can patch the job description so that the job only looks at the first 100 LEI records, making it easy to do a quick test of the job.
He were will show a sample of the job description for the LEI site so you can get some idea of what it looks like in the RDF Turtle language. This sample loads data from the LEI file supplied by the GLEIF, converts it to RDF, sends it to the triple store, and indexes a few fields in Lucene:
@prefix : <http://rdf.ontology2.com/mogrifier1/>
@prefix g: <http://rdf.ontology2.com/graph/>
@prefix e: <http://rdf.ontology2.com/environment/>
@prefix es: <http://rdf.ontology2.com/elastic/>
@prefix lei: <http://rdf.legalentityidentifer.info/vocab/>
:Mogrifier :scanPackage "com.ontology2.definancialization.artifact" .
[] a :LEIReaderArtifact ;
:name e:reader .
[] a :DatasetArtifact ;
:name e:tdb ;
:path "tdb" .
[] a :GraphArtifact ;
:name e:lei ;
:containedIn e:tdb ;
:graphURI g:lei ;
:input e:reader .
[] a :LuceneArtifact ;
:name e:fulltext ;
:input e:reader ;
:path "lucene/lei" ;
:field [
a :FieldDefinition ;
:property lei:RegisteredName ;
es:index "analyzed";
:fieldName "name"
],[
a :FieldDefinition ;
:property lei:RegisteredCountryCode ;
:fieldName "country"
],[
a :FieldDefinition ;
:property lei:LegalEntityIdentifier ;
:fieldName "lei"
],[
a :FieldDefinition ;
:property lei:LEIAssignmentDate ;
:fieldName "assigned" ;
:transform <java:com.ontology2.rdf.mogrifier.fn.ZuluDate>
] .
Rather than covering everything in detail, I'll point out a few major points:
- At the top we find declaration of a few namespaces. The namespace mechanism for RDF is quite a bit like the namespace mechanism in XML, except that it is simpler as some rough edges have been sanded away. Namespaces allow us to combine terms that are meaningful in different contexts without the risk of a conflict. In this case we use the default
: namespace for terms that are meaningful to the mogrifier, but we add terms from some other namespaces, such as:
-
lei: to refer to terms defined for the LEI projectes: to refer to terms that are used in ElasticSearch configuration files. These terms map 1-1 to e: to provide a convenient place for the names of artifacts defined by the system
The mogrifier is tightly integrated with the Java programming language and runtime environment:
- By specifying a Java package name with the
:scanPackage predicate, the mogrifier searches for artifact definitions on the Java classpath and discovers metadata that is written on them with java annotations
- the
:transform predicate takes the name of a plain ordinary Java function. Unlike many databases and systems which require user defined functions (UDFs) to be written with special calling conventions, the mogrifier can often automatically import Java functions, converting the arguments and return value to RDF values. (In other cases it needs a little bit of metadata to help)
Note that the job definition doesn't care about the order that artifacts are defined. Instead, it analyzes the linkages between artifacts made through fields such as :input to determine the order of dependencies, much like the famous make utility. Often the system can take advantage of parallelism between steps: for instance, it can use different threads for parsing, search indexation, and writing to the TDB database. It operates efficiently, parsing the file once, and sending the result to multiple places. Once the TDB database is complete, the reports and record matching can then be run at the same time.
For maximum flexibility, the mogrifier is divided into several parts including:
- Artifact Factory: each Artifact consists of multiple Java objects. For instance, the
LuceneArtifact produces one object that indexes RDF graphs when the database is being built, and another object embeded in the web site to support search. An Artifact can also create different implementation objects based on context, such as one designed for local execution and another designed for a scalable cluster. The artifact factory manages the creation and configuration of all the objects needed in the execution.
- Control Plane: once a job is compiled, an RDF graph and set of Jena Rules is built to control execution. The job is defined into a number of flows, and when the prerequisites for a flow are met, a rule fires to trigger execution of the flow. When the flow is complete, facts are inserted into the control graph which trigger more flows until execution is done. The control plane manages the initialization and teardown of all the artifacts so that everything is left in the correct state.
- Data Plane:The control plane does its work by sending commands to the data plane, which is interchangable. The default implementation of the data plane is based on the Reactor framework from Pivotal which is incredibly efficient for jobs that run on a single workstation or server and also supports flows that work on a streaming basis, as well as batch. The organization of the data plane is quite similar to Spark, Flume and other big data frameworks so there is a clear path to scaling for cluster execution.