Rapid Knowledge Base Construction
Bending the cost curve
Great advances were made in the 1970s and 1980s toward knowledge-based systems which could do seemingly intelligent things such as identification of molecules, medical diagnosis, speech recognition and the planning of complex tasks. Despite initial success, however, the primary obstacle to further commercialization was the high cost, in terms of human labor, of creating and maintaining the required knowledge base.
Machine learning methods of all kinds have come a long way in recent years, these have had success at tasks such as visual recognition for which symbolic AI proved unsuited. However, most forms of machine learning requires the curation of ever expanding and collection of labeled test and training data -- a process which may or not be cheaper than the process of encoding knowledge explicitly. Many companies, such as Nuance have developed products such as Dragon Medical, which perform well but were created at great cost and without a roadmap to construct similar products that cover different domains.
Ontology2 has pioneered a form of rapid knowedge base construction that combines large and heterogenous shared databases (such as Wikidata, DBpedia, Legal Entity Identifiers, etc.) with public and private data to rapidly produce knowledge bases tailored for specific applications. Combining statistical quality control with crowdsourcing, machine learning, network analysis and a number of "unreasonably effective" tricks, our methodology puts data to work faster than ever before.
Global Reach
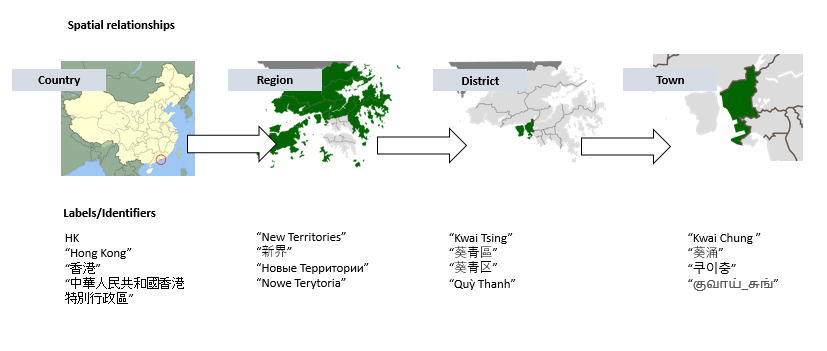
One benefit of Linked Data data sets, particularly DBpedia and Wikidata, is that they have global coverage, both in terms of geography and language. For our Legal Entity Identifiers project, we needed to determine the legal jurisdictions that are relevant for business addresses, no matter what country they are in or what language they're written in. Starting with multilingual labels (ex. "서울 means Seoul in Korean") and spatial containment relations (ex. "Oregon is part of the United States") from :BaseKB, our house edition of Freebase, we added a handful of patches and rules to construct a system that identifies where an address is located and which country, state and local jurisdictions apply to it.
The multilingual nature of the semantic web is particularly important in markets such as EMEA (Europe, Middle East, and Africa) in which more than 200 languages are spoken. In the past, localization has been an expensive proposition, but today, multilingual knowledge bases powered by open Linked Data are a force multiplier that lets organizations of all sizes complete on the global stage.
A Solution for Reference Data
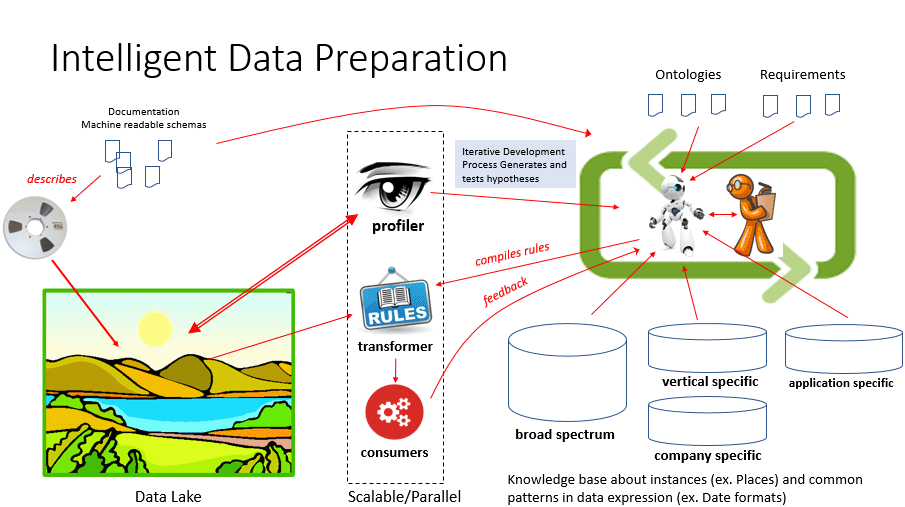
Almost all businesses require some form of reference data: largely this is data about entities in the outside world such as customers, vendors, counterparties, as well as products, geographical descriptions and industry-wide taxonomies and ontologies. It is important to be aligned with outside data sources, but it is even more important to express your organization's own view of the world.
The slide above illustrates how this can be done: as input, we get data, as well as metadata about that data and as much information as we can get about the system the data came from. We would also ingest information about requirements for the data into an issue tracking system. We incorporate information from a wide range of data sources, including the blending of information with varying scope, such as that of an industry, a company, or any subunit of a company.
We say it involes a "data lake" because we profile (study, inspect) and transform the data with scalable tools that can easily repeat the transformation process as many times as requirements demand.
Coming Full Circle
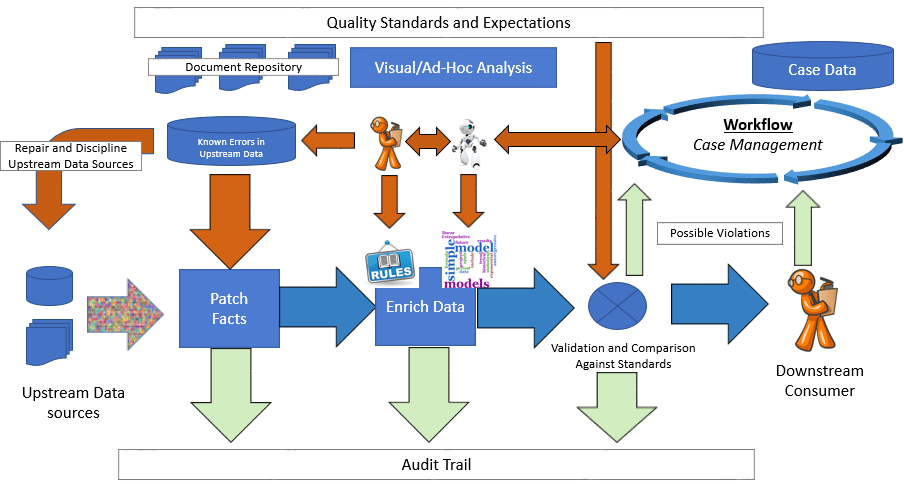 The diagram above pictures a advanced and fully developed reference data management system. The system tracks changes in upstream data sources, can disagree with those sources by patching facts, and has a large toolbox spanning both "old" and "new" AI to enrich the data. It puts the data into confrontation with a database of known results and the demands of end users through a Case Management system. Cases can be resolved by improving the import process or, when the input data is wrong, "agreeing to disagree" with it as well as working with to get the data changed at the source.
The diagram above pictures a advanced and fully developed reference data management system. The system tracks changes in upstream data sources, can disagree with those sources by patching facts, and has a large toolbox spanning both "old" and "new" AI to enrich the data. It puts the data into confrontation with a database of known results and the demands of end users through a Case Management system. Cases can be resolved by improving the import process or, when the input data is wrong, "agreeing to disagree" with it as well as working with to get the data changed at the source.