It's dangerous to go alone
Can't find or retain staff with the skills you need?
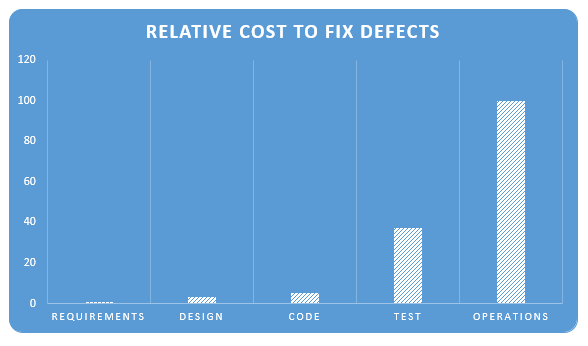
"In some circumstances, rework and redesign might also be considered costs of redundancy that are triggered by low-trust behavior. In software development, as much as 30% to 50% of expenditures can be on rework. In manufacturing, rework costs can often exceed the original cost of producing the product."
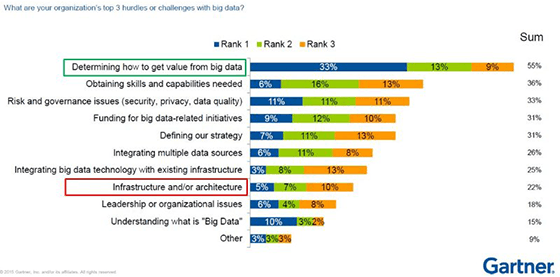
Struggling to get value from data, machine learning, text analysis or predictive analytics?
Project late or out of control?
-- National Aeronautics And Space Administration
Starting a high-risk/high-reward project?
"Nearly eight out of ten organizations have big data projects underway, but only 27% describe their efforts as 'successful,' and a scant 8% as 'very successful.' ... despite this ... 60% of executives ... say big data will 'disrupt their industry'
Take This!
Ontology2 strategy
With intense engagements, Ontology2 puts you in control of tough problems by developing a methodology that takes the critical factors for success with your specific problem into account. This can be broken down into three parts:
Context |
Process |
 Content |
- Context
- Ontology 2 will form a task force to attack your problem that typically has three to five members, some of which are from your organization and some of whom we supply. We will work you hard to extract your knowledge of your problem, make it explicit, and build it into the solution. Problems beyond the grasp of an individual can be tackled surely by a high-trust team with the right resume.
- Process
- Our approach to the problem depends on the complexity of the problem. We can take one of three routes (1) Simple problems are dealt with quickly by routine methods. (2) Slightly more complex problems are addressed by the "Continuous Improvement" methods associated with W. Edwards Deming and Joseph Juran. (3) For highly complex problems, the various forms of complexity must be enumerated and individually managed. We create a custom "agile" process that addresses all critical aspects of the problem and ensures that we make sufficient progress in all ncessary areas to produce a viable product.
- Content
- Reusing as many existing parts as possible, the task force creates a modelling language, and then a model, for the problem domain. With RDF/K, our extension to RDF, we can can extract models and instances directly from existing data, code and documents. We can hold these complementary (and sometimes contradictory) models side by side and work on them with common tools for analysis, visualization and learning. With the foundation in place, we can apply the "80/20%" rule to focus effort on fixing the most common and problematic causes of error. Our Real Semantics software can be used as a modelling tool or incorporated into your product.
Ontology2 tactics
There are a number of specific methods we can use to create, discover, and share expert knowledge within your team.
- Pair Work
- Via teleconference or site visits, 2 can deliver expert help with programming or management tasks to organizations anywhere in the world. Delivered in 8 to 24 hour intensives, pair work maximizes our ability to gather ground truth and share experience and expertise.
- Training, Coaching and Documentation
- A wide range of knowledge is necessary to succeed at technical projects today. Never has there been a wider range of training materials available in classroom, video, and text form. Some subjects are best studied systematically, while others are best "learned on the job" by applying a new tool to a specific problem. Often, critical knowledge about your systems and problems is unknown or scattered in the heads of multiple people. With the need understood, Ontology 2 can link you to training materials, deliver training, coach individuals, and lead the documentation process for internal knowledge.
- Lightweight Modeling
- Over the last two decades, immense progress has been made on methods for modeling both problem domains and software systems: UML, Topic Maps, and OWL are a few specific specifications -- multiple communities have been working in parallel and making steady progress. Our approach is less centered around standards and tools as it around creating models accurately from existing artifacts and presenting models to the people who work on the system in their own language.
Ontology2 special technical expertise
Computing involves many kinds of knowledge, some of which are timeless and universal, such as mathematics, and others of which are specific to languages, domains
- RDF, Graph Databases, and General-Purpose Knowledge Bases
- Our experience with RDF-based technology and related graph databases is particularly strong. Our work on databases such as DBpedia and Freebase has been pioneering, and has evolved since into methodology and tools that use RDF as a "universal solvent" for all data structures commonly used in computer applications.
- Java and JVM Languages
- Ontology 2 experience is comprehensive when it comes to Java and other languages that run on the JVM, including the ecosystem of software libraries used for JVM languages. Our Real Semantics framework is written in Java and provides deep visibility into both the static and dynamic structure of Java programs with the ability to map artifacts such as classes, members, constants, javadocs and source code for Java systems as well as transform live instances of Java objects into graphs that can be queried, reasoned on, and stored in a wide range of databases and formats.
- Build and Configuration Systems
- Like it or not, software development is based around a "Run, Break, Fix" model. Rapid progress depends on being able to make a small change, quickly check that it works, and incorporate it into a shipping product without error. If developers are complaining that work is slow because the build is slow, or if it is hard to onboard new developers, you have a serious situation and should take action. Ontology 2 is expert at optimizing build systems. This disciplined thinking applies to configuration and dependency management tools such as the Spring framework -- if your developers find Spring a source of problems instead of solutions, you need a master plan to control the configuration of your app.
Get Your Project On Track
Contact inquiries@ontology2.com to get the help you need.