Source Code transclusion in HTML
Introduction
Software documentation frequently contains examples of code and the results of running the code. For instance, the Tutorial and Example Queries for the Ontology2 Edition of DBpedia 2016-04 is a typical example, as is this chapter about turning CSV to RDF.
Software code can be embedded in HTML by using the pre element and escaping a handful of characters that have a special meaning in HTML, particularly replacing the < angle bracket with < and the & amperstand with &. This is not hard to do on a small scale, but if you are incorporating tens or hundreds of code snippets to create a book size document, this becomes tedious -- particularly if you are changing the code and documents frequently.
Some languages (such as the Bash Shell and XML) have escaping mechanisms such as here document and CDATA sections that make it easy to embed foreign text without escaping individual characters. Although XHTML supports CDATA, ordinary HTML does not. One answer to this problem is to write documentation using a language like Github-flavored Markdown, any system of embedding code in a markup language will have corner cases when you embedding code written in that language. Although markdown is an easy language to use, it doesn't have the rich support for semantic tagging that is possible in HTML.
Even if the technical difficulties of embedding source code in documentation are solved, we've still got the problem of catching typos in the documentation and also making sure that the documentation keeps up with the code. Often the difficulty of keeping documentation up to date leads to a hostility towards producing any documentation at all. The most practical answer is for every example in the documentation to be built into a test case, and then transclude the examples into the documentation. Much like the practice of literate programming the close integration of code and data makes it possible to create and maintain better documentation at lower cost.
In Real Semantics, code samples can be included by using the HTML object element. Documentation is written as a collection of HTML 5 documents which are parsed by the docminister component to transclude software code into documentation. This realizes the benefits mentioned above, as well as making it possible to do special kinds of transformation and markup (such as highlighting and pretty printing) as well as the construction of an inventory of code snippets that are integrated into the documentation
Case Study: The NPI example
On the page npi-csv-to-rdf.html there is an example where a SPARQL query against RDF data is demonstrated. In this case we are taking a small RDF model (contained in a file) and running a SPARQL query (also contained in a file) against it.
In the documentation, the input RDF file is displayed with the following markup:
<object data="inclusions/nppes-folded.ttl" type="text/plain"></object>
When Real Semantics compiles the documemntation, the contents of the inclusions/nppes-folded.ttl file is transcluded like this:
@prefix nppes: <http://rdf.ontology2.com/nppes/property/>.
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
[ nppes:Entity_Type_Code "1" ;
nppes:Is_Sole_Proprietor "X" ;
nppes:Last_Update_Date "2007-07-08"^^xsd:date ;
nppes:NPI "1679576722" ;
nppes:Other_Provider_Identifier [
nppes:Identifier "1553" ;
nppes:Issuer "BCBS" ;
nppes:State "NE" ;
nppes:Type_Code "01" ;
nppes:index 2
] ;
nppes:Other_Provider_Identifier [
nppes:Identifier "46969" ;
nppes:Issuer "BCBS" ;
nppes:State "KS" ;
nppes:Type_Code "01" ;
nppes:index 4
] ;
nppes:Other_Provider_Identifier [
nppes:Identifier "046969WI" ;
nppes:State "KS" ;
nppes:Type_Code "04" ;
nppes:index 6
] ;
nppes:Other_Provider_Identifier [
nppes:Identifier "93420WI" ;
nppes:State "NE" ;
nppes:Type_Code "04" ;
nppes:index 3
] ;
nppes:Other_Provider_Identifier [
nppes:Identifier "B67599" ;
nppes:Type_Code "02" ;
nppes:index 5
] ;
nppes:Other_Provider_Identifier [
nppes:Identifier "645540" ;
nppes:Issuer "FIRSTGUARD" ;
nppes:State "KS" ;
nppes:Type_Code "01" ;
nppes:index 1
] ;
nppes:Practice_Location_Address [
nppes:City_Name "KEARNEY" ;
nppes:Country_Code "US" ;
nppes:Fax_Number "3088652506" ;
nppes:First_Line "3500 CENTRAL AVE" ;
nppes:Postal_Code "688472944" ;
nppes:State_Name "NE" ;
nppes:Telephone_Number "3088652512"
] ;
nppes:Mailing_Address [
nppes:City_Name "KEARNEY" ;
nppes:Country_Code "US" ;
nppes:Fax_Number "3088652506" ;
nppes:First_Line "PO BOX 2168" ;
nppes:Postal_Code "688482168" ;
nppes:State_Name "NE" ;
nppes:Telephone_Number "3088652512"
] ;
nppes:Provider_Credential_Text "M.D." ;
nppes:Provider_Enumeration_Date "2005-05-23"^^xsd:date ;
nppes:Provider_First_Name "DAVID" ;
nppes:Provider_Gender_Code "M" ;
nppes:Provider_Last_Name "WIEBE" ;
nppes:Provider_License_Number [
nppes:Number "12637" ;
nppes:State_Code "NE" ;
nppes:index 1
] ;
nppes:Provider_Middle_Name "A" ;
nppes:Specialization [
nppes:Primary_Taxonomy_Switch "Y" ;
nppes:Taxonomy_Code "207X00000X" ;
nppes:index 1
]
] . Note that transclusion is triggered by the use of the text/plain MIME type of the object element; as the system develops, additional MIME types will be supported and the transclusion will be configurable by the use of the param element and other elements enclosed in the object element.
To continue the example, the NPI also contains a SPARQL query which is run against the the above RDF model, which is embedded with the following HTML code:
<object data="inclusions/nppes-folded.sparql" type="text/plain"></object>
which inserts the following into the document:
prefix nppes: <http://rdf.ontology2.com/nppes/property/>
select ?npi {
[
nppes:NPI ?npi ;
nppes:Specialization/nppes:Taxonomy_Code "207X00000X" ;
]
} The source code for the Real Semantics Book is embedded in a Maven project and thus we can include Java code in the src/test directory. Thus we can test that the two files above are syntactically correct and give the correct result with a JUnit test.
package com.ontology2.rdf.docminister;
import ...;
public class NPPESExamples {
@Before
public void init() throws Exception {
new DirectInjector().inject(this);
}
@EmbedModel("inclusions/nppes-folded.ttl")
Model nppesFolded;
@EmbedSparql("inclusions/nppes-folded.sparql")
Query sparql2;
@Test
public void lookupOrthoSurgeonFolded() {
QueryExecution elizabeth= QueryExecutionFactory.create(sparql2,nppesFolded);
ResultSet rs=elizabeth.execSelect();
assertTrue(rs.hasNext());
assertEquals("1679576722",rs.next().get("npi").asLiteral().toString());
}
}
This test is run when we construct the book, and the book does not go "to press" (get installed on the Ontology2 web site) unless the test works. Thus I've got no fear that the book contains broken examples or that examples might break in the future when the code changes.
A "Central Dogma" For Testing and Training
Unit testing is one of the most important advances in software engineering. By incorporating a number of tests which are run whenever a project is built, we can ensure that subsystems have certain behaviors and that the subsystems will continue to have these behaviors as the code changes over time.
Possibly the most important idea in the 456 pages of Michael Feather's book Working Effectively with Legacy Code is that unit tests need to be fast. This is because it is important for the run-break-fix development cycle to be fast as waiting for code to compile is a major time sink (computer performance) and also that human attention spans are taxed by long development cycles (human performance.) Unit Tests should be small and self-contained; tests that depend on external components are called Integration tests and are much more expensive to run. Integration tests are important too, but they usually can't be run as often as unit tests. As unit tests are fast, you can write large numbers of them, and thus have robust confirmation of system behaviors.
In Real Semantics, there is a "Central Dogma" of testing which parallels the Central Dogma of Molecular Biology. This is because many tests can be written such that information flows in a specific way, just as data flows from DNA to RNA and then to synthesized proteins inside a living cell.
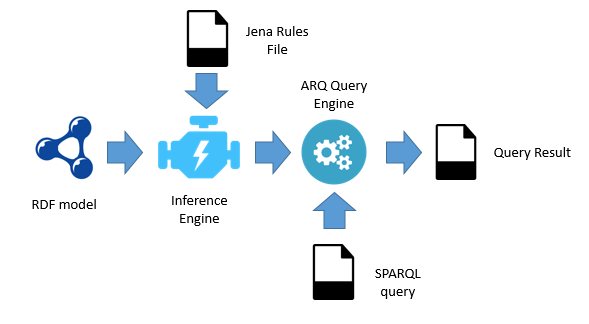
The core idea is that many semantic web tasks can be performed by the combination of three things:
- An RDF model, or graph, that contains data
- A set of inference rules that act on the model to infer new facts
- A SPARQL query
(The case above is simplified because there are no inference rules)
If you were using a conventional relational database, say MySQL or Microsoft SQL Server, you'd run into the problem of working with an external database engine, making sure that it starts out and ends in a predictable state. I've seen many projects where people use the same database, with the same schema and/or table names, for tests built into the build process and for manual experimentation. If you don't have a way to isolate these activities, building your code could "nuke" information in your database that you'd like to keep and can become a serious source of stress. The most modern way to manage this problem would be to run the database in a virtual machine or container that is created just for the task, but this adds to the build time, which is inevitably going to be extended if the tests depend on an external server.
Working with RDF, SPARQL, and Jena we've got a better option, which is to take advantage of Jena's ability to do inference and run queries against a small in-memory model. (Real Semantics uses in-memory models much the way hashtables are used in dynamic languages such as Python.) In-memory models can be created and torn down quickly, so there is very little overhead involved in using them for tests. (For larger production data sets you might use Jena's on-disk TDB storage engine, access a TDB engine remotely via Fuseki, or use any of a large number of third-party SPARQL databnses that support the SPARQL protocol.)
The ability to transclude source code into HTML, together with the ability to transclude foreign source code into Java objects, makes it possible to split out small test cases to demonstrate the behavior of datasets, inference rules, and SPARQL queries -- not only ensuring the correctness of code, but also providing a framework for creation of high quality documenation, both for RDF technologies such as SPARQL, but also for rule sets and queries based on RDF.
Conclusion
Real Semantics is all about finding multiple purposes for artifacts such as code, data and models. One aspect of this is that, as much as possible, we represent artifacts as parse trees that let us operate on artifacts such as HTML documents and Java classes with meaninful operators. Real Semantics rejects the use of text templating for HTML, and instead uses the JSoup library to manipulate HTML DOM trees. This in turn lets us weave together text from multiple HTML documents together with programming language source code of all kinds, backed up with automated tests, to link rich text with models and code, making documentation that is transparent to various classes of users.