Real Semantics is written with Java, so it has many accomodations to Java. Some programming languages, like the Bash shell, let you write multiple-line strings, like so,
load_rdf <<EOF
@prefix : <http://example.com/>
:John :friendOf :Mary, :Alice, :Bill .
EOF
Java does not let you do that, so it is awkward to embed languages such as Turtle, SPARQL and the Jena Rules language in Java, as well as other languages like SQL. Our answer to that is a specialized dependency injection mechanism that provides a simple and standardized mechanism to connect Java code with bits and pieces of source code in other programming languages.
In other programming languages, such a facility could be less important. For instance, Python and C# have multiple-line quotes, so embedding Turtle and SPARQL code is easier. On the other hand, the mechanism used in Real Semantics is multiple-use. Not only are queries and data embedded in the places where you use them, but Real Semantics can also make a catalog of all the queries and data that are embedded in the code, looking at the software in the holistic way necessary required for long-term maintainance, debugging, and analysis of security and performance.
Here is the actual Java code that loads an RDF model (data) and a SPARQL query, executes the query on the graph, and captures the result set. This action occurs throughout the Real Semantics code, but this particular example is copied directly from a test case:
@Test
public void queryAModel() throws Exception {
DirectInjector.get().inject(this);
ResultSet rs=QueryExecutionFactory.create(query,model).execSelect();
QuerySolution s1=rs.next();
assertEquals("http://example.com/Good", alignment(s1));
assertEquals(45,totalGold(s1));
// .. more tests that we got back a good result set
}
@EmbedSparql
Query query;
@EmbedModel
Model model;
The first line of the function uses the DirectInjector, which is the initial implementation of the embedding facility. Commonly this function is called in the constructor or other initialization method of a class, but we call here it so it is visible. The DirectInjector finds Query and Model fields that are marked with annotations such as @EmbedSparql and @EmbedModel The system look for a Java Resource with a default name and location, parses it, and injects it into the fields of the test class.
A Java Resource is a file that is in the java CLASSPATH, which could be on the computer's filesystem, in a JAR file or otherwise loadable by the Java classloader. This is an ideal mechanism to package queries, small knowledge bases as well as things such asimages and audio files together with the Java code that use them.
By default, the @EmbedX annotations look for a resource file in the same namespace as the class being injected, with a name derived from the name of the field with an added filename extension such as query.ttl or model.ttl. These files are stored in standard locations in the source code. As seen in my IDE (IntelliJ Idea), the Java classes and the corresponding resource files go into similarly named subdirectories of the src/test/java and src/test/resources directory:
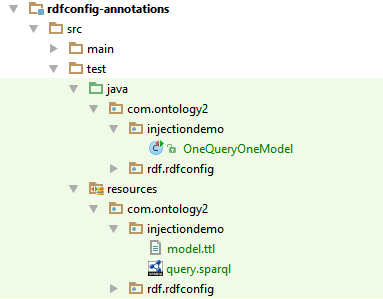
In the build process, either the IDE or Maven compiles the Java class; both the compiled .class file and the resources are copied into the same directory:
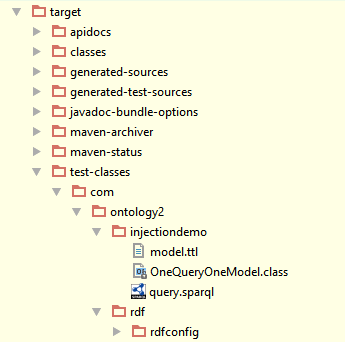
All in all this is a straightforward way to package your resources together with your Java Code. Obviously your Java code can access these resources, but Real Semantics can access it too in ways you might not plan for at first, such as the creation of audit trails and other sorts of documentation. It's best to stick with the standard practice because it is easy to implement and avoids the risk of conflicts between similarly named resources by using Java's namespace mechanism, but if you must, you can provide a specific resource name that you'd like to inject like so:
@EmbedModel("../another/package/aPopularModel.ttl")
Model myCopyOfAPopularModel;