Introduction¶
In my last essay I described the problem of filtering Hacker News to produce a purified feed. My viewpoint, motivation and idea of what constitutes a "good" posting is described there, so read it if you're interested.
Since then I've developed a classifier that produces an enriched feed. In this article I'll describe the classifier, show you the results, and show some evaluation information.
The overall methodology is like that used in the machine learning literature, where I split a labeled sample of articles into a training and a test set, create a model, and then test the model by comparing predictions it makes to my own evaluations.
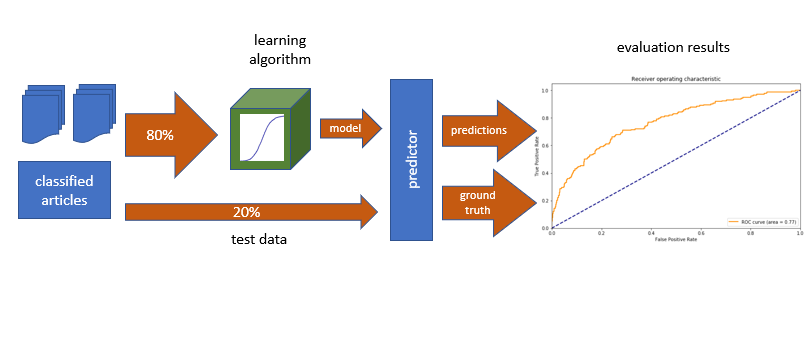
what's unusual about this article is that it applies this technique to a problem that I formulated from the beginning, applying the evaluation methodology to confirm fitness to purpose, as opposed to entering into a competition to get better results on a pre-existing data set.
Along the way I will explain how my model works, what the output that I see looks like, and how some changes to the system affect the quality of results, with an eye to understanding what the training requirements for a more general feed classifier would be.
A working model¶
Here is the information that I have for an article in the training set:
Input Features¶
My classifier only looks at tokens that appear in the title. The tokens are produced by the nltk_tokenize function: some of these tokens are words, others are punctuation. It is common in this kind of work to eliminate the most common words (stopwords) and to eliminate words that are less common (because these are not well sampled.) For now, I keep everything, because the classifier I am using (logistic regression) can handle a large number of features, both in terms of execution speed and in terms of realistically estimating how much weight to put on both highly common and highly rare features.
For each word in the vocabulary, there is a feature: the value of that feature is 1 if the word is present in the title, and 0 if it is not. The input matrix looks like:
Alternative bag-of-words features¶
I'll quickly review some things that I could be doing differently, but am not.
Many text retrieval systems perform stemming:
A stemmer for English, for example, should identify the string "cats" (and possibly "catlike", "catty" etc.) as based on the root "cat", and "stems", "stemmer", "stemming", "stemmed" as based on "stem". A stemming algorithm reduces the words "fishing", "fished", and "fisher" to the root word, "fish". On the other hand, "argue", "argued", "argues", "arguing", and "argus" reduce to the stem "argu" (illustrating the case where the stem is not itself a word or root) but "argument" and "arguments" reduce to the stem "argument".
Intuitively, stemming should improve the performance of a classifier when the number of training examples is small. For instance, if "cat" is a relevant word for a category, "cats" probably is too, and we'll collect better statistics for word occurence if we group them together. On the other hand, this assumption might not always be true: for instance, it could be that "CAT" bulldozers are what's relevant. Also, most stemmers do some violence to the text by committing some errors.
Another possible improvement would be to ignore certain words. For instance, there is little value in words that occur only once or a few times, since whether they appear or not in documents which are relevant or not is just a matter of chance. Words that occur very often (say "the") are also unlikely to be predictive and are frequently treated as stop words.
Some ML algorithms do poorly when they are confronted by a very large number of features, others do better. Logistic regression, the algorithm I use, holds up pretty well, particularly if it is predictions that we want as opposed to insights.
Sticking with the bag-of-words model, I could also weight words based on how often they occur in the title (So that The Global Fund to Fight AIDS, TB and Malaria: A Response to Global Threats, a Part of a Global Future would count the word "Global" three times.) I could also weight words less if they occur frequently in the corpus as well as normalize the length of the title vector. Put those together and I'd get a tf-idf vector.
The case for the tf-idf vector could be stronger if I was using whole documents, but my experience and reading of literature seems to indicate that these choices don't usually make a big difference in the performance of the classifier.
Beyond bag-of-words¶
Another place I could be going is beyond bag-of-words, to features that are sensitive to the position and order of words.
One scourge of Hacker News is articles of the form "X is down"; it might make sense to build this in as a handcrafted feature, but asking an algorithm to find it is tricky because the number of possible multiple-word phrases expands exponentially as the number of words increases. The training samples thus get divided more and more finely, and it is hard to tell if correlations we see are real or just the result of luck.
People get small amounts of lift on classification tasks like this using features such as Word2Vec, but I am currently unimpressed. To do significally better than bag-of-words, we need something that models and understands language pretty well.
Output labels¶
The training labels are 1 if an article is considered relevant, 0 if it is not. Here is a sample of the labels that the classifier is trained and tested on:
Note that our task is a bit unfair for two reasons:
- Its not always possible to tell what an article is about from the title. Some titles are descriptive, others are not.
- Sometimes I evaluate articles by looking at just the title, but often I read the article. My judgement on an article is not just based on relevance, but also on quality. There are many spammy websites full of tensorflow tutorials, whistlestop summaries of the data science literature stuffed with ads, etc. I vote them down.
If I were just trying to replicate my ability to look at a title and guess at relevance and I wanted to tune it up to maximum accuracy, I would change the task. I might create a "neutral" category and only judge documents on the basis of the title.
The classifier¶
Fortunately, the classifier I use is good at learning probabilities. Thus, if some fraction of articles with "Tensorflow" in the title are irrelevant, it builds that into its probability estimate.
The classifier I use is the Logistic Regression classifier from scikit-learn with the default parameters. I've tried other parameters and found settings that perform worse, but none that perform markedly better.
Note the decision function looks like:
$$ \beta_0+\beta_1x_1+\beta_2x_2+\cdots+\beta_mx_m = \beta_0+ \sum_{i=1}^m \beta_ix_i $$
where the $\beta$(s) are the learned coefficients and the $x$(s) are the inputs. Note that the $x$(s) are zero or one depending on the absence or presence of a token, so the output of the classifier is the sum of the weights for all of the words that appear in the title added to the intercept $\beta_0$ and the document is considered relevant if the sum is greater than zero and irrelevant if it is less.
Note there are other algorithms such as linear regression, linear support vector classifier, multinomial naive bayes, perceptron, et al. that train the same decision function but may choose different weights. These algorithms may generalize better or worse than logistic regression; in the little testing I have done these have not performed notably better in accuracy but have often performed much worse in terms of CPU time.
Negative weights, therefore, indicate words that are found in irrelevant titles, and positive weights indicate words found in relevant titles:
Adding up these weights produces a log-odds score, which can be converted to a probability with an inverse logit function. If the log-odds function is zero, the predicted probability is 0.5; the naive way to get predictions is to predict that the article is relevant if the log-odds is positive, and negative if it is zero.
The trouble with that is that if we look at the predicted probabilities, most of them are very low, before 0.2.
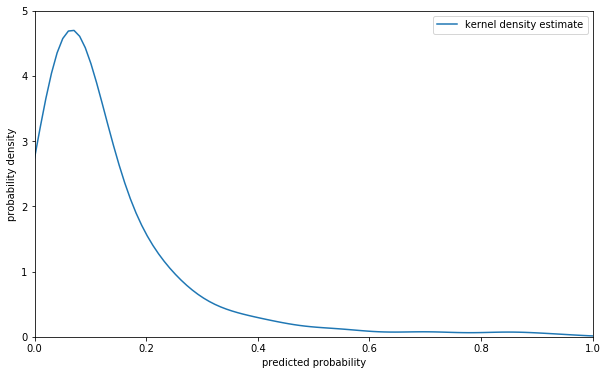
If I looked only at articles with a predicted probability of 0.5 or above, I wouldn't get many articles at all. Most of the relevant articles have a probability less than 0.5. This is the case because I judge fewer than 10% of the articles to be relevant.
To get a good article feed I will have to set a threshold well under a probability of 0.5; if I do so I will see irrelevant articles, but far fewer than if I tried to look at the whole feed.
The world through my eyes¶
Currently I am browsing Hacker News with an interface that shows me a selection of top rated articles. As I write this, I have 487 in the queue. For quite a while I have been browsing a random selection of 25% of the articles -- I find that this is around the limit of what I can look at. Thus I pick out the top 120 articles:
The ultimate way to evaluate a real-world system is: "does the customer like it?", "what value does it create, etc.". Statisical evaluation is valuable for commercial systems in so far as it supports that goal. Looking at the list above, I'm pretty happy. For instance, in the above sample, Hacker News got swamped with articles about an own goal scored by Ethereum that caused the loss of $280 million dollars. (I could have told them so, but they wouldn't have listened -- thus I'm not interested) A few articles about it show up at the bottom of the list, which I can accept. (Note that many of these are rejected by the filtering that happens before the machine learning model.)
But how well does it work, really?¶
For many reasons, it is tempting to evaluate performance with a single number. That's important for competitions on Kaggle and ImageNet, but less so in the real world.
As is the case with logistic regression, most classifiers return some kind of confidence value which can be handled with a varying cutoff point that lets us make a trade between getting fewer positive results with higher precision as opposed to more positive results with worse precision.
To evaluate the performance of the system, we need to split up the data set into a training set and a test set. For this experiment, I use a 80% train and 20% test split.
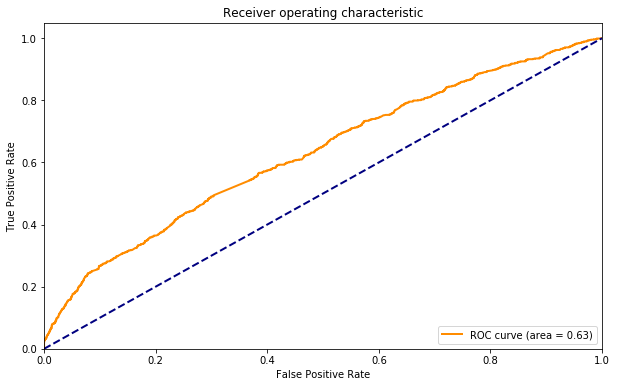
I illustrate the tradeoff by plotting the Receiver Operating Characteristic curve:
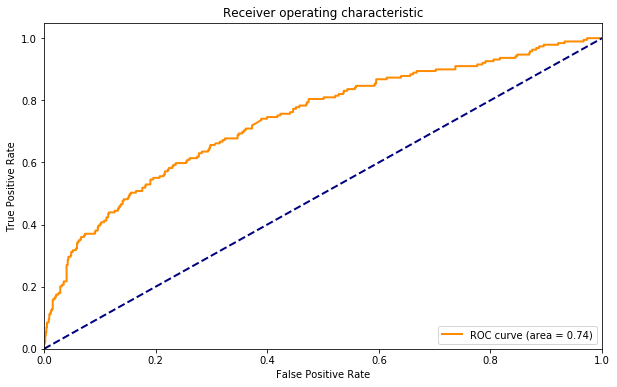
This curve illustrates the tradeoff: if I set a high confidence threshold, I am in the lower left corner. Clearly there is a range where I can get 20% or so of the wanted articles with a tiny fraction of unwanted articles. We can get around 60% of the wanted articles with a false positive rate of 20%, and 80% with a false positive around 50%.
Going to upper right, however, there is still a hard core of good articles that will be hard to get without tolerating feed which is mostly irrelevant. That's life. If I read Hacker News without any filter that's what I would get.
Practically one might be concerned with a particular operating point, or, in my case, I feel that I can look at a certain number of postings a day and want to make the most of that. Looking at the curve helps you make choices, but if you want to tweak the algorithm and know if it got better or worse, you still need to distill "quality" down to one number, and that number is the area under (the) curve for the receiver operating characteristic, or the ROC AUC.
For the plot above, the area is 0.76. The diagonal line on the plot represents the case of a classifier without predictive value, and corresponds to an AUC of 0.5.
It's not hard to make a plot that is that bad by making a bad model. For instance, if I use just 1% of the data for training (57 samples) I get a model that hasn't learned anything.
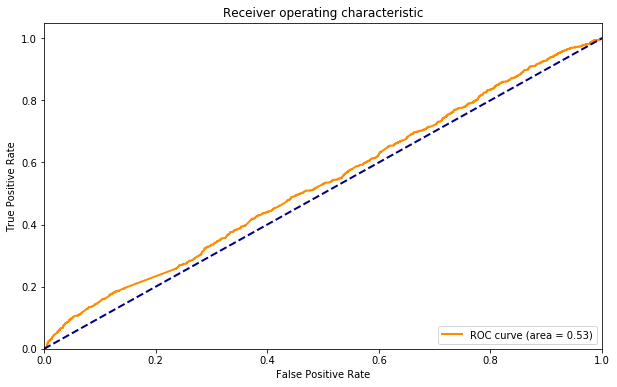
That's an important point, because it takes quite a few judgements to train a text classifier -- that's one reason why text classification hasn't become more widespread (and why Relevance Feedback hasn't set the world on fire.)
I think many people would expect to start getting good results with 5 or 10 judgements, but this system is doing poorly with 50. Real-world success, therefore, involves setting realistic expectations and gathering hundreds, if not thousands, of judgements.
How many judgements does it take to make a good model?¶
That's a good question, and fortunately scikit-learn gives us the tools to answer it.
The technique is straightforward: I just compute the ROC curves using different amounts of training data. The green curve below is the one to look at, as it represents the AUC ROC for the test data. The red curve represents the AUC ROC for using the training data -- the results look a lot better when we use the training data because the model is overfitting; even though it is learning something relevant to the test data, it's learned how to cheat on the training data, finding words that can identify and classify most of the individual titles in the data set:
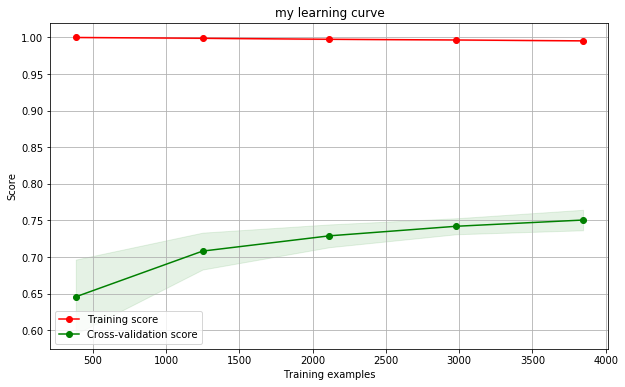
I don't know exactly how to map the ROC AUC to how satisified I would be with the output, but looking at the error bars, I'd imagine that I'd be happy with the results if I had 1200 training samples; maybe even 500. On the other hand, the AUC seems to be reaching an asymptope around 0.75 and it seems likely that I wouldn't get dramatically better results by adding more training data to this model.
I zoom in on the case of low numbers of training samples in order to get a sense of where learning starts:
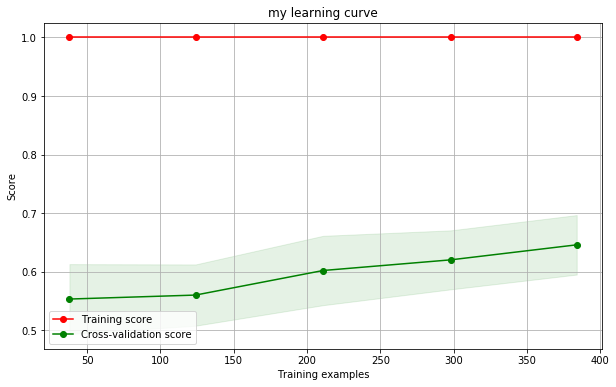
The error bars seem to clearly be pulling away from the 50% mark when we have somewhere between 100 to 200 examples. Using 2% of the data for training (115 samples) the ROC curve is visibly pulling away from the diagonal:
The user's subjective experience is the real metric here, so if I look at the sorted predictions with 115 training samples, they really aren't bad:
Looking at the graphs, it seems there is a threshold between 50 and 100 training examples where the results go from "artificial stupidity" to "artificial intelligence": at 57 samples, the model only seems to have learned that it likes pdf files:
The consolation prize is that this model knows that it sucks (something good about logistic regression.) It never predicts that a posting has more than a 50% chance of being relevant, so if we set the decision threshold of 50%, it predicts that everything is irrelevant.
What about other features?¶
One ground rule of this analysis is that I'm only using information available from the Hacker News link, which includes the title, the submitter, and the url. We've seen that the title is fairly predictive.
What about the user?
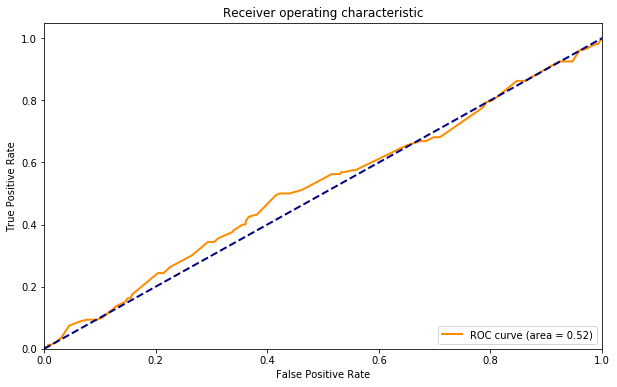
I would have thought that I would have some 'friends' and 'foes' on HN, but it seems like the submitting user is not at all predictive of relevance.
To double check, here are some of the predictions.
Those are pretty bad. In contrast, I get much better results using url hosts as a feature. (Like the badhosts mechanism used in the prefilter)
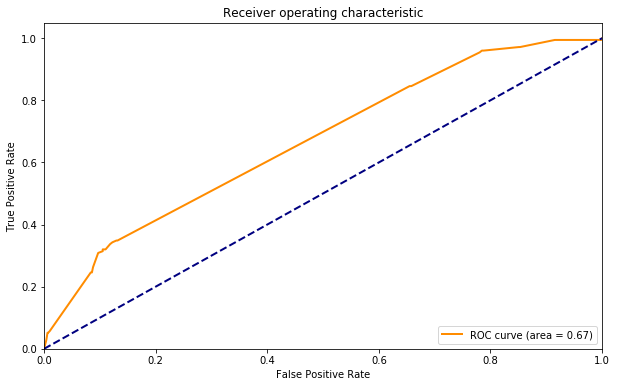
Looking at the RoC curve it seems that the hostname is highly predictive at the high-relevance and low-relevance sides of the curve, probably because there are a few sites that host a large number of articles which are balanced towards one direction or the other. Here are the top and bottom predictions:
Although the ROC AUC looks pretty good (better than I got for 117 training examples using words;) the top and bottom don't look so good to me.
Since we do seem to get some value out of the hostnames, what if we use the title words, submitters and hostnames to make one big model? The AUC is a touch better than what we get from using just the words (0.77 vs 0.74)
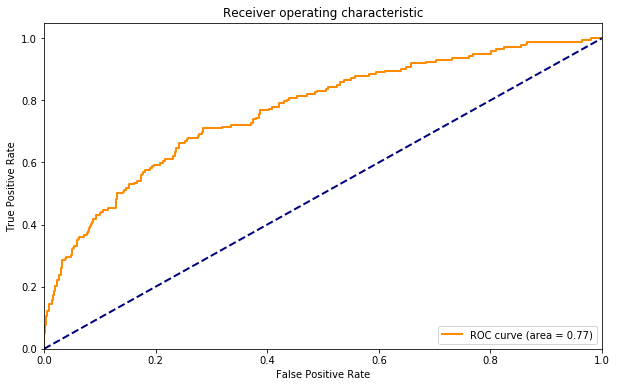
Next time I run my model (probably this evening) I will switch to the joint model since it seems to perform a bit better.
Conclusion¶
Trained on roughly 5000 examples, a simple text classification model based on words in the title has proved effective for improving the relevance of a feed of articles from Hacker News. (See my last essay for my definition of "relevance".)
A model based on the submitter of the article was completely ineffective, and a model based on the hostname where the article is based was less effective than the word-based model. Adding both of those features improves relevance a bit on the ROC AUC (Reciever Operating Characteristic Area Under Curve) metric.
Although I might be able to do better by tweaking the features or using a different classifier than Logistic Regression, I am not inclined to mess with this model much more because a model based on the title and hyperlink is missing a large amount of information which could only be found on the target webpage. I'll be looking to that for future improvements, but that is going to involve beefing up the information harvesting system and probably some performance work on the machine learning side since the amount of text will increase greatly.
The one area where I did explore the parameter space was in the size of the training set. Particularly, this system seemed to learn nothing of value when given 57 training examples but it did visibly seem to learn when given 114 examples. Although the results improve when we use more training examples, there does seem to be a minimum number examples required to get meaningful results. Without some major change in the algorithm, therefore, classifiers that want to get across the "commercialization valley of death" will need to coax users to classify more documents than they might want to initially.