Introduction¶
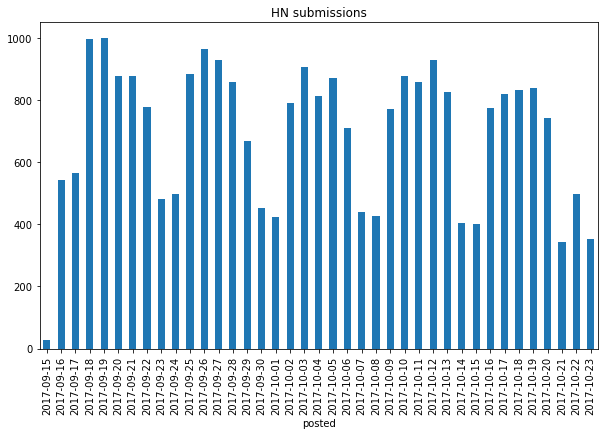
Hacker News is one of the best sources for news in the intersection of technology and business. Hacker News gets nearly 1000 submissions on a busy weekday, and quite a bit less on the weekends:
Much of the value of Hacker News is that it is somewhat curated; the "Hacker News Guidelines" state the following:
What to Submit
On-Topic: Anything that good hackers would find interesting. That includes more than hacking and startups. If you had to reduce it to a sentence, the answer might be: anything that gratifies one's intellectual curiosity.
Off-Topic: Most stories about politics, or crime, or sports, unless they're evidence of some interesting new phenomenon. Ideological or political battle or talking points. Videos of pratfalls or disasters, or cute animal pictures. If they'd cover it on TV news, it's probably off-topic.
Despite this, the Hacker News homepage sometimes seems dominated by a few stories about "the usual suspects", whereas many good stories never get a second a vote. I see Hacker News as a way to connect with a global community, but the sheer bulk of the submissions means I'd get lost in the noise if I tried to read everything relevant.
In this article, I report on the first phase of a project to develop a system, a machine learning model if you will, that produces a highly condensed stream of articles relevant to me. This system is immediately useful to me, but I also hope to generalize it into something useful to others who are looking for actionable information in a stream of documents.
Values Clarification¶
Towards An Ecology of Mind¶
A mission statement is important for a project like this because, in process of teaching a machine to make subjective judgements, you need to sharpen your definitions. Here are some reasons:
- So you can split hairs more consistently.
- So you can maintain a stable viewpoint over time
- So you can maintain a stable viewpoint across multiple raters.
Let me start with what it is I want:
- To connect with people who can help me and who I can help
- To improve my software development practice particularly focused around Python and Java
- To better understand the management of software projects
- To learn about the marketing of software projects and services
- To get information that is actionable, that not everybody has
- I am particularly interested in: machine learning, code generation, SAT/SMT solvers, model-driven development, rules engines, and particularly in applying advanced methodologies to improve outcomes and extend the range of what both professional and non-professional programmers can do.
The Gentle Art of Psychic Self-Defense¶
Here is what I don't want:
- I have a limited amount of time and energy to read articles; I don't want to be overloaded with topics I am uninterested, or wade through people endlessly saying the same things
- Much of people's media use is addictive in character. In some cases (pornography, video games) this is focused around trying to feel good, but often (in the case of "news" and "opinion") it seems to be about making yourself feel bad. Somehow, though, you keep coming back for more. "Fake News" is at least as dangerous for being "News" as it is for being "Fake". I don't want it.
- Some content pushes my own buttons and messes me up emotionally. I don't have time for it.
I am certainly interested in helping others with this, but one thing I do know is that it can't be done as a free service. Free services make you the commodity and are ultimately about using (and controlling) you.
What they don't tell you about NLP¶
In the 1970s and 1980s, there was vast enthusiasm for "Expert Systems" which would use a set of hundreds, if not thousands, of rules to imitate the performance of skilled persons, such as a doctor making a diagnosis.
In the mid 1970s, for instance, the MYCIN expert system outperformed members of Stanford's medical faculty. Yet, doctors were not ready to sit at a keyboard and consult with a minicomputer, and it was soon perceived that developing expert systems was a labor intensive and expensive process.
Sometimes it seems little has changed; IBM Watson recently struck out after at three year project to fight Cancer.
Today's machine learning approaches make it easier to solve problems, once they are formulated and a training set is developed, but the process of creating training sets can be expensive as the old "knowledge aquisition" process. Much progress in machine learning has centered around public data sets such as the MNIST Digits, Kaggle competitions, and ImageNet. These data sets are helpful for testing that your code works, improving algorithms, and even developing a generalizable approach to machine learning.
Public data sets are not helpful, however, for developing commercial applications of deep learning, because they don't teach you how to develop your own training sets.
Capturing Human Knowledge¶
Machines have some limits.¶
In the early 2000s I worked on a project with Jae-Hoon Sul and Thorsten Joachim to use the SVM to classify abstracts from the arxiv.org preprint archive. For topics that had 10,000 examples, the system performed about as well as a human. For topics that had 50 examples, the system was useless.
I was optimistic and I thought text classification was on the verge of widespread commercialization. I was wrong.
Today, classifiers that use some kind of dimensional reduction can get much better results with a small amount of data (say 1000 judgements) most people aren't going to want to classify 50 documents, and if they do, they're going to want much better results than they are going to get.
Humans have some limits¶
If you work all day at it at reasonable tasks, you can probably make about 2000 up or down judgements a day. In an eight hour day, that would be 15 seconds per judgement.
I do other things, but I can imagine spending about an hour a day training my system on a sustained basis. That amounts to a budget of 200 judgements. In 5 days I can make 1000 judgements (enough to start training a model with) and over the course of a year I can make more than 70,000 judgements.
Safely looking at the Sun¶
I am looking for the cream of the crop from Hacker News, something like the top 95% of articles. If I looked at a random sample of articles, I'd spend most of my time saying "No!"; it would drive me crazy and fatigue would be a problem (I would blast right by a relevant article.)
Making judgements with 5% selectivity contributes just 0.29 bits worth of information per judgement. From the viewpoint of contributing information, its much more efficient to make judgements with 50% selectivity. Practically, people "tune out" when they are talking with a person or a system that doesn't seem to be listening to them, so it is much easier to recruit and retain people (even yourself) if you give them a task that seems meaningful.
Thus, before I collect any judgements I had to set up some kind of filter that would make the task tolerable, if not pleasant.
Say something once, why say it again?
A Rule is worth at least 5 judgements¶
One answer to the "knowledge acquisiton bottleneck" in both rules-based and machine learning systems is to build a rule-based system in parallel with a learning system. Effort gets focused on places where the rules and the learning system disagree.
To take a simple example, one annoying kind of HN post is
"X is down"
or
"Is X down?"
I don't want to see those articles, I just don't. Accurately Learning either of those patterns with "bag of word" features is impossible since the word "down" is common. You might do better with bigrams or some similar kind of feature, but if you increase the number of features dramatically, you need more training data.
On the other hand, the above two patterns can be defined quickly with a pair of regexes.
To add rules efficiently, you need the ability to add a rule and quickly check what effect it has on the decision process (to be sure it doesn't have unintended consequences.) This paper reports that it takes about 75 seconds to define and test a rule, and if we can add rules that quickly, it's efficient to write rules if a rule can save making five judgements.
An irrelevance model¶
The following section describes a wide variety of articles that, from my viewpoint, pollute Hacker News. Many of these are fine categories, but the sheer number of repetitive articles about them drives me crazy. Others are pure poison. These categories overlap and are sometimes contradictory. I've put more thought into this than into what it is I want because: (i) there is much more irrelevant content than there is relevant content, and (ii) I'd like to be suprised by relevant things that I don't know about.
In conventional information retrieval, we can distinguish between
- relevance: a function of both a document and a query (is this document relevant to a query?) A tf-idf score is a relevance score.
- quality: a function of a document (is this a good document?) PageRank is a quality score.
In practice, these things are conflated: for instance, queries about medicine should probably use a different quality model than queries about other topics, since medicine faces a particular challenge from quack information. When I look at large numbers of documents that I'm not interested in, they all seem to blur and look the same (repetitive.)
In the case of filtering, relevance is highly user dependent. (Maybe you care about React and Angular but can't bear reading about Tensorflow and PyTorch.) Quality is less user dependent, although it still varies. You probably agree pop-in windows are bad, for instance, but you might think I am overly harsh towards Medium.
Below I note many kinds of posting which I personally find undesirable, as much as this may read like a localized version of A More Humane Mikado or a proposal to open new circles in Hell.
Mainstream Media¶
The New York Times and Bloomberg Businessweek are good examples. Some of this content is valuable, but much is sensationalistic. An article in one news publication is frequently parroted in other publications. Almost none of the information is actionable. (Some months it seems that every week of Businessweek has an article about some situation that I knew about already because I had a peripheral involvement of some kind.)
All of this information is available outside HN; I subscribe to the Economist and Bloomberg Businessweek and sometimes watch the NBC Nightly News. If you want to read the New York Times, get a subscription.
This sort of content can be filtered out easily by the badhosts mechanism, so it is an efficient way to reduce the volume of data, judgements necessary, and my time taken up.
Not-so Mainstream Media¶
The Huffington Post is one example. The MSM does reporting; bottom-feeding sites report on other site's reporting. Bye-bye!
I like Ars Technica, I like it enough that I read it regularly and don't need to see HN links to it. On the other hand I think TechCrunch is trash with the exeception of one one author; she doesn't write for them anymore so I have no reason not to badhost them.
Paywalls¶
Hacker News doesn't have the spine to block articles behind paywalls, but I do. Even in cases where there is a work-around (10 free articles a month from the NY Times) I often wouldn't be able to see enough articles to evaluate a meaningful sample of them. Once the mainstream media is cut, the next major offender is commercial scientific journal publishers.
Pop-ins¶
This is the most annoying trend on the web today, and nobody seems to know what to do about it:
Medium, for instance, tries to scam you by looking like the "10 free articles" warning from the NY Times and hoping you'll think that registration is required, or that the harassment will stop when you log in with Facebook.
Pop-ins are annoying on the desktop and are especially annoying on mobile where it might not even be possible to dismiss them.
I wish I could make them go away entirely, but I can make my system filter them out so I don't have to see them in links from my system. I wish I had an automated solution (Contact me if you have any ideas!) but this offense is typically on a per-site, not per-article basis, so it is a job for badhosts.
The Badhosts Mechanism¶
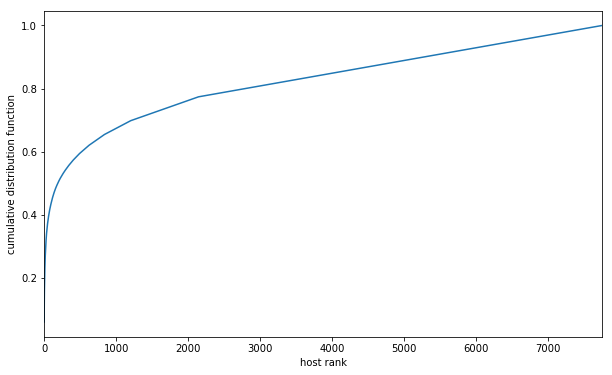
I can take a large bite out of the above forms of undesirable content via the "Badhosts Mechanism" which blocks postings based on the hostname of the URI. Here are some common (and uncommon) hostnames; all but two of the top 20 hosts are blocked, and I am thinking about blocking one of them:
The cumulative distribution function is a good way to visualize this kind of thing: the top 190 sites receive 50% of the postings; the straight section that occurs past rank 2000 is comprised entirely of hosts that occur just once.
The Keyword Mechanism¶
To address other kinds of unwanted content, I have to use different features. The one that I've implemented to make the labeling managable is a block on keywords in the HN post title. The title is tokenized into individual words, and words filtered out of the resulting list, so that it is not possible (yet) to block on multiple-word phrases or to block words that occur in particular positions. (ex. "X is down").
Here are the top 20 blacklisted keywords.
The keyword mechanism has other weaknesses: no matter how smart we can make our model, the title is incomplete. You can judge a book by its cover, but you'll have an upper limit on your accuracy. Longer term I'll need to make something deeper (and I'm already crawling whole articles that pass the two filters so I'll have something to work with.)
Apple¶
I'm sorry, but I just don't care about the latest iPhone and don't have the time for the endless handwringing about which MacBook to buy, your plans to abuse Apple's return policy, how the Apple Watch isn't quite perfect, etc.
When I first started looking at postings, I felt overwhelmed with Apple articles, and convinced that HN readers had an unhealthy obsession with Apple. The data shows a slightly different story:
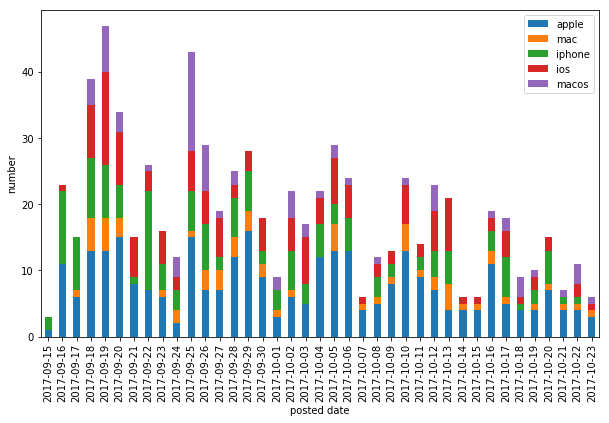
Apple really was an overwhelmingly popular topic in the first few days, probably because of the September 12 product launch data this year.
Facebook, Uber, ..¶
Big companies behaving badly. There is plenty of this in TechCrunch, The New York Times, The Economist, etc.
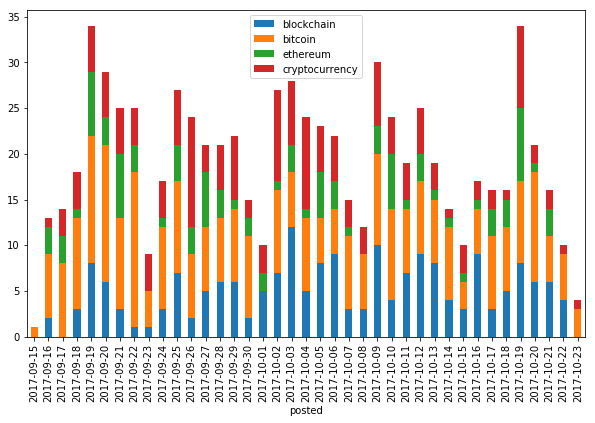
Cryptocurrencies¶
I for one have no fear of missing out. Unlike Apple, interest in cryptocurrencies has been constant throughout the last month.
Security Panics¶
I am interested in reverse-engineering (particularly when assisted by model-driven techniques or automation such as American Fuzzy Lop. New security panics happen all the time, however, and when they are at their peak, the volume of articles can seem overwhelming:
This is an example of why the model has to be non-stationary; there may be automated ways to control bursts of article, but the distribution of topics in the article stream will change over time so that the model will never be entirely finished -- it just has to be possible to maintain it with a small amount of effort.
Dogpiling¶
Speaking of which, one of the symptoms of "pageview journalism" is that many people jump into action to write thin articles about topics as soon as they get public attention. The mainstream and not-so-mainstream media are common offenders (ex. this article from Jalopnik which reports on an Economist article) Another common offender is the blogger who sees somebody else's blog post go viral and rapidly turns out a quickly written rebuttal.
It's hard to resist the conclusion that blocking subjects of interminable discussion will block some dogpiling, but a real answer may involve looking for emerging topic clusters, network relationships between articles, etc. Adding a time delay before some articles in appear in the output feed may help us get better features to address this.
Popular programming languages that I don't use¶
This should be my most controversial decision.
Front-end specialists are in demand these days; where else can you learn something new every five minutes and then find your skills are out of date in a week? If I gave React the consideration it deserves, I wouldn't have time to look at anything else (or so it feels.)
I think the idea of Rust is interesting, I thought Cyclone was interesting too; I've read the docs in detail while spinning at the gym. I find it depressing though to see people working hard to do very simple things, so for now I am sticking with managed languages.
Haskell is a special case. When people can't figure out how to do something in PHP, they say "PHP is stupid". When they can't figure out how to do it in Haskell they conclude that "I am stupid." Thus we get "this is my 15th blog post how about deep monads are; I thought I got it right last time, but..."
I could do the same for Cold Fusion, Delphi, Tcl/Tk, FORTRAN, COBOL, Smalltalk, etc. except the number of articles on those languages are small enough that they don't get in the way.
Videos, Podcasts, etc.¶
If I am rating 100+ articles a day I just can't spend the time it takes to look at time-based media.
Science, Medicine¶
I find this interesting, and that's a problem. If I start reading this, hours will go by. Science and Medicine also have their own version of the dogpiling problem. Colliding neutron stars are big news, but I don't need to see tens of articles on the topic.
Startup Pornography¶
I'm all for working on product and talking to customers.
I'm not interested in gossip about famous investors, "we are proud to announce that we've been funded", "we are proud to announce that we've been acquired" (unless I want to steal your customers), hand-wringing about the startup that you cannot or will not start, or anything that indicates that you're more interested in getting funded than you are in building a business.
Software version releases¶
Github is second only to medium as a hostname for postings. Github is not badhosted because there is a lot of interesting content there. I probably will put a block on
https://github.com/[^/]*/[^/]/releasesbecause thousands of releases of software are made a day of software that I don't care about. (At least they don't all get posted to Hacker News.)
Salami and other form of thin content¶
The most insidious threat I see is the practice of dividing content into small slices. A relatively benign example is here. Like a Tom's Hardware article, it is divided into gratuitious sections to increase the pageview count. Across the three articles it covers a lot of ground, but it does it so quickly that I'm not sure people would get much out of reading it.
Some articles say very little with few words, some articles say very little with a lot of words. Occasionally an article really says too much. Often articles are impossible to evaluate because they can only be understood if you know the a number of obscure buzzwords and acronyms.
The long and short of it is that identifying Salami will take different features from identifying topics. Writing a regex to catch things like "79 ways to stop wasting time on the Internet" may be part of it, but it will take more to stamp it out.
The first month of judgements¶
It turns out that the keyword blacklist is less effective than the badhosts mechanism. The keyword blacklist eliminates an additional 9.8% of postings. The main impact is emotional; I don't have to spend mental energy on things that bug me, making it easier to make it a habit to work through each day's list.
In the first few days I worked through all of the articles that made it through the two filters, but soon I found that overwhelming and rather than putting in more effort to make a better prefilter, I started taking a sample of just 25% of articles on most days, occasionally looking at more on the weekends when I have time. Thus I actually have evaluated about 40% of articles that have not been blocked.
Here is the breakdown:
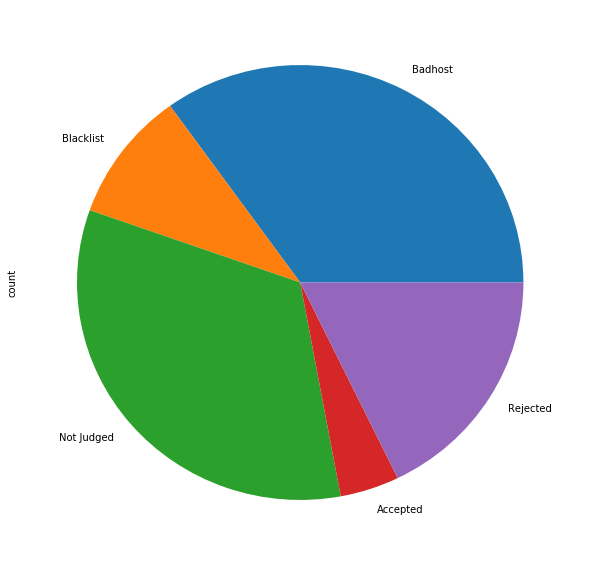
To wargame this, let's imagine that I didn't take a random sample of postings to evaluate, but instead I looked at them all (and that I accepted and rejected the same percentage.)

About 10% of postings would be accepted, the other 90% are rejected. Half of them are already rejected by the badhosts and keyword mechanisms, the other half would be rejected manually.
If the future model makes the same decisions I do, it would accept roughly 10% of HN articles, or about 2950 articles. That comes to about 80 articles a day on average. Even on peak days, that would come under my 200 article a day limit to scan. The HN front page has 30 articles a day, so this would be something like scanning a completely refreshed front page between two and three times a day. Alternately, to produce one "front page" a day, I'd have to increase selectivity by a factor of two to three.
Next Steps¶
If I could reproduce my judgements, it seems I could make a managable stream of articles to look at. Thus I feel good about moving forward.
The next step, pretty obviously, is to develop a simple feature set (probably bag of words in the titles) and start training classifiers. Scikit-learn offers a fairly wide choice of algorithms with a uniform interface that will make it pretty straightforward to try different things.
Really good performance will require custom features, derived both from the HN metadata (beyond-word patterns in the title, votes, submitters) as well as metadata and content from the referenced article. It will also require more data, which will come as long as I look at 100-200 articles a day. An early goal will be the development of a probability estimator which will let me produce a feed of articles that I'm mostly likely to like (which might not be the same as "quality") and also a feed of marginal articles which, presumably, will be the most informative for me to rate.
Contact me at paul.houle@ontology2.com if you find this interesting and you'd like to talk.
Appendix¶
Articles that I liked¶
Here's a chance to see what you think about my preferences.
Here is a random sample of 30 postings that I liked, exclusive of text-only articles. (I see those in a different stream in my interface and I am less selective for them.)
I don't stick perfectly to my own standards because: I hadn't finalized them when I started judging, I make "fat finger" mistakes, and I'm human. (I have a soft spot for Ripple)
Articles I didn't like¶
Note the sample I am showing you is not a random sample of "articles I've judged" since I'm showing the same number of positive and negative examples: