A naive translation
RDF is often compared to Topic Maps, UML and similar systems for high-level modelling and metadata. It can do all that. However, RDF is also applicable to ordinary data of all kinds. We're going to address the data translation in two phases: first a naive translation which is not informed by any understanding of the data format, and then an adapated format which embeds knowledge about the structure of the data and makes it easier to work with the data.
Working on the NPI data dump from the NPPES, we see it is a pretty typical CSV file stored inside a ZIP file, albeit with a huge number of fields. We'll turn the header and the first row sideways so they'll fit on your screen:
| NPI | 1679576722 |
| Entity Type Code | 1 |
| Replacement NPI | |
| Employer Identification Number (EIN) | |
| Provider Organization Name (Legal Business Name) | |
| Provider Last Name (Legal Name) | WIEBE |
| Provider First Name | DAVID |
| Provider Middle Name | A |
| Provider Name Prefix Text | |
| Provider Name Suffix Text | |
| Provider Credential Text | M.D. |
| Provider Other Organization Name | |
| Provider Other Organization Name Type Code | |
| Provider Other Last Name | |
| Provider Other First Name | |
| Provider Other Middle Name | |
| Provider Other Name Prefix Text | |
| Provider Other Name Suffix Text | |
| Provider Other Credential Text | |
| Provider Other Last Name Type Code | |
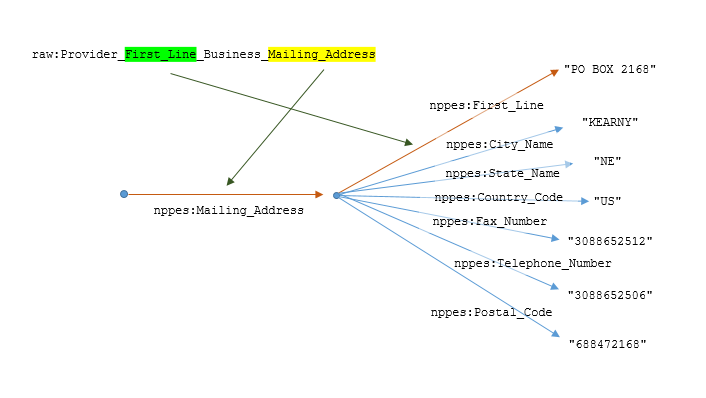
| Provider First Line Business Mailing Address | PO BOX 2168 |
| Provider Second Line Business Mailing Address | |
| Provider Business Mailing Address City Name | KEARNEY |
| Provider Business Mailing Address State Name | NE |
| Provider Business Mailing Address Postal Code | 688482168 |
| Provider Business Mailing Address Country Code (If outside U.S.) | US |
| Provider Business Mailing Address Telephone Number | 3088652512 |
| Provider Business Mailing Address Fax Number | 3088652506 |
| Provider First Line Business Practice Location Address | 3500 CENTRAL AVE |
| Provider Second Line Business Practice Location Address | |
| Provider Business Practice Location Address City Name | KEARNEY |
| Provider Business Practice Location Address State Name | NE |
| Provider Business Practice Location Address Postal Code | 688472944 |
| Provider Business Practice Location Address Country Code (If outside U.S.) | US |
| Provider Business Practice Location Address Telephone Number | 3088652512 |
| Provider Business Practice Location Address Fax Number | 3088652506 |
| Provider Enumeration Date | 05/23/2005 |
| Last Update Date | 07/08/2007 |
| NPI Deactivation Reason Code | |
| NPI Deactivation Date | |
| NPI Reactivation Date | |
| Provider Gender Code | M |
| Authorized Official Last Name | |
| Authorized Official First Name | |
| Authorized Official Middle Name | |
| Authorized Official Title or Position | |
| Authorized Official Telephone Number | |
| Healthcare Provider Taxonomy Code_1 | 207X00000X |
| Provider License Number_1 | 12637 |
| Provider License Number State Code_1 | NE |
| Healthcare Provider Primary Taxonomy Switch_1 | Y |
| ⋮ | ⋮ |
| Healthcare Provider Taxonomy Code_15 | |
| Provider License Number_15 | |
| Provider License Number State Code_15 | |
| Healthcare Provider Primary Taxonomy Switch_15 | |
| Other Provider Identifier_1 | 645540 |
| Other Provider Identifier Type Code_1 | 01 |
| Other Provider Identifier State_1 | KS |
| Other Provider Identifier Issuer_1 | FIRSTGUARD |
| Other Provider Identifier_2 | 1553 |
| Other Provider Identifier Type Code_2 | 01 |
| Other Provider Identifier State_2 | NE |
| Other Provider Identifier Issuer_2 | BCBS |
| Other Provider Identifier_3 | 93420WI |
| Other Provider Identifier Type Code_3 | 04 |
| Other Provider Identifier State_3 | NE |
| Other Provider Identifier Issuer_3 | |
| Other Provider Identifier_4 | 46969 |
| Other Provider Identifier Type Code_4 | 01 |
| Other Provider Identifier State_4 | KS |
| Other Provider Identifier Issuer_4 | BCBS |
| Other Provider Identifier_5 | B67599 |
| Other Provider Identifier Type Code_5 | 02 |
| Other Provider Identifier State_5 | |
| Other Provider Identifier Issuer_5 | |
| Other Provider Identifier_6 | 046969WI |
| Other Provider Identifier Type Code_6 | 04 |
| Other Provider Identifier State_6 | KS |
| Other Provider Identifier Issuer_6 | |
| ⋮ | ⋮ |
| Other Provider Identifier_50 | |
| Other Provider Identifier Type Code_50 | |
| Other Provider Identifier State_50 | |
| Other Provider Identifier Issuer_50 | |
| Is Sole Proprietor | X |
| Is Organization Subpart | |
| Parent Organization LBN | |
| Parent Organization TIN | |
| Authorized Official Name Prefix Text | |
| Authorized Official Name Suffix Text | |
| Authorized Official Credential Text | |
| Healthcare Provider Taxonomy Group_1 | |
| ⋮ | ⋮ |
| Healthcare Provider Taxonomy Group_15 |
We also took the liberty of replacing a large numbers of empty numbered fields with ellipsis. It might be one's first impression that it's outrageous to have 50 groups of 4 columns for "Other Provider Identifiers", but that's the kind of difficulty you have expressing this kind of information as a CSV. (Practically, ZIP compression encodes the empty fields efficiently. Health care data formats, such as HL7, often put specific limits on the length of fields and the number of values for multi-valued fields. Although unlimited length formats are fashionable today, limits do protect against buffer overflows, people putting a Microsoft Word document into a text field, "enterprise" databases that have a limit on the length of primary keys, crashes caused by blowing out the stack, and other problems.)
Note a few other details. Almost all of the fields in this data file are ordinary strings. Some of them are nominal numbers which identify entities (such as a social security number.) It doesn't make sense to add, subtract, multple or divide nominal numbers, so there is no need to tag them as a numeric type, say xsd:integer or xsd:float. In fact, it would be harmful if we did use a numeric type for these numbers because then leading zeros would be truncated, which would make the numbers invalid for their intended use.
To convert the above CSV record to an RDF record, we first create a blank node which represents the record itself. We then attach properties to the type, naming the properties with a simple mechanical translation of the field names to URIs. Specifically, we convert spaces to underscores, then we run the data through the XPath function encode-for-uri (although this function is defined in the XPath specfication, it is useful in RDF and is implemented in the Jena framework.) This function is designed exactly to do this, and we get:
@prefix raw: <http://rdf.ontology2.com/nppes/raw-property/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
[
raw:Entity_Type_Code "1" ;
raw:Healthcare_Provider_Primary_Taxonomy_Switch_1 "Y" ;
raw:Healthcare_Provider_Taxonomy_Code_1 "207X00000X" ;
raw:Is_Sole_Proprietor "X" ;
raw:Last_Update_Date "2007-08-07"^^xsd:date ;
raw:NPI "1679576722" ;
raw:Other_Provider_Identifier_1 "645540" ;
raw:Other_Provider_Identifier_2 "1553" ;
raw:Other_Provider_Identifier_3 "93420WI" ;
raw:Other_Provider_Identifier_4 "46969" ;
raw:Other_Provider_Identifier_5 "B67599" ;
raw:Other_Provider_Identifier_6 "046969WI" ;
raw:Other_Provider_Identifier_Issuer_1 "FIRSTGUARD" ;
raw:Other_Provider_Identifier_Issuer_2 "BCBS" ;
raw:Other_Provider_Identifier_Issuer_4 "BCBS" ;
raw:Other_Provider_Identifier_State_1 "KS" ;
raw:Other_Provider_Identifier_State_2 "NE" ;
raw:Other_Provider_Identifier_State_3 "NE" ;
raw:Other_Provider_Identifier_State_4 "KS" ;
raw:Other_Provider_Identifier_State_6 "KS" ;
raw:Other_Provider_Identifier_Type_Code_1 "01" ;
raw:Other_Provider_Identifier_Type_Code_2 "01" ;
raw:Other_Provider_Identifier_Type_Code_3 "04" ;
raw:Other_Provider_Identifier_Type_Code_4 "01" ;
raw:Other_Provider_Identifier_Type_Code_5 "02" ;
raw:Other_Provider_Identifier_Type_Code_6 "04" ;
raw:Provider_Business_Mailing_Address_City_Name "KEARNEY" ;
raw:Provider_Business_Mailing_Address_Country_Code "US" ;
raw:Provider_Business_Mailing_Address_Fax_Number "3088652506" ;
raw:Provider_Business_Mailing_Address_Postal_Code "688482168" ;
raw:Provider_Business_Mailing_Address_State_Name "NE" ;
raw:Provider_Business_Mailing_Address_Telephone_Number "3088652512" ;
raw:Provider_Business_Practice_Location_Address_City_Name "KEARNEY" ;
raw:Provider_Business_Practice_Location_Address_Country_Code "US" ;
raw:Provider_Business_Practice_Location_Address_Fax_Number "3088652506" ;
raw:Provider_Business_Practice_Location_Address_Postal_Code "688472944" ;
raw:Provider_Business_Practice_Location_Address_State_Name "NE" ;
raw:Provider_Business_Practice_Location_Address_Telephone_Number "3088652512" ;
raw:Provider_Credential_Text "M.D." ;
raw:Provider_Enumeration_Date "2005-05-23"^^xsd:date ;
raw:Provider_First_Line_Business_Mailing_Address "PO BOX 2168" ;
raw:Provider_First_Line_Business_Practice_Location_Address "3500 CENTRAL AVE" ;
raw:Provider_First_Name "DAVID" ;
raw:Provider_Gender_Code "M" ;
raw:Provider_Last_Name "WIEBE" ;
raw:Provider_License_Number_1 "12637" ;
raw:Provider_License_Number_State_Code_1 "NE" ;
raw:Provider_Middle_Name "A"
] .
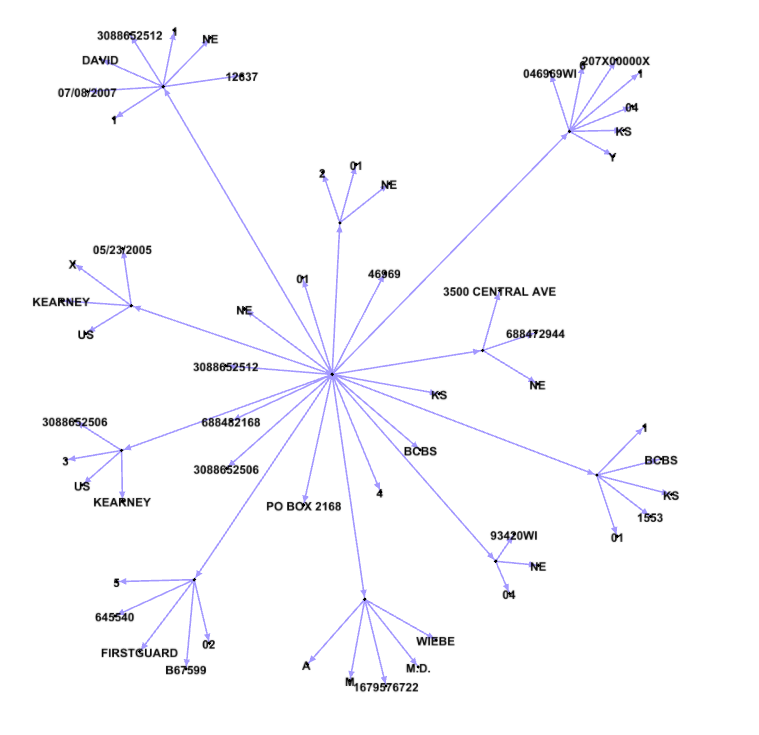
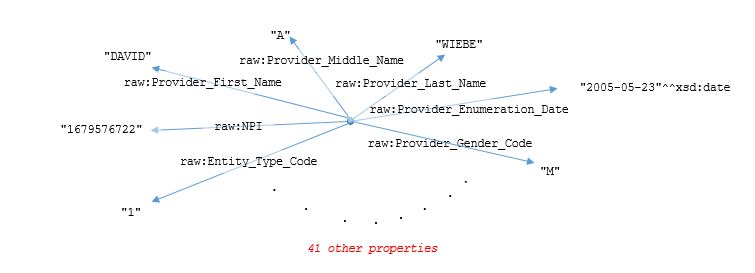
If we draw this as a graph, we get something that I like to call a "hedgehog" because the properties all radiate out from a single point, the blank node. The following graph shows just a few of the 48 properties from this example:
Only one more bit of translation is necessary, which is converting dates of the form "05/23/2005" to the XML Schema form: "2005-05-23"^^xsd:date, or better yet, "2005-05-23-05:00"^^xsd:date because NPPES is based in Fargo, ND. For an application focused in the United States, the timezone doesn't matter because NPPES is only open during the business day. Yet, for international applications, such as the LEI, you really will run into cases where it does matter. (Although the Pearl Harbor attack happened on Dec 7, 1942 in Hawaii, Emperor Hirohito received a phone call notifying him about the successful attack early in the morning of Dec 8, 1942) For this particular file (and quite a few others) an effective rule is to transform fields fields to xsd:date if the property name ends in "Date".
We can load these records into a triple store and start writing SPARQL queries right away with the caveat that it is awkward to handle cases where the fields are numbered, since we'll often need to search multiple properties, for instance, if we want to find Orthopaedic Surgeons, we would look for the taxonomy code "207X00000X" in Healthcare_Provider_Taxonomy_Code_1, Healthcare_Provider_Taxonomy_Code_2,... all the way through Healthcare_Provider_Taxonomy_Code_15. You can do this with SPARQL:
prefix raw: <http://rdf.ontology2.com/nppes/raw-property/>
select ?npi {
[
raw:NPI ?npi ;
?taxonomyCodePredicate "207X00000X" ;
]
filter strstarts(str(?taxonomyCodePredicate),
"http://rdf.ontology2.com/nppes/raw-property/Healthcare_Provider_Taxonomy_Code_")
}But that's not saying you should do it. Converting the predicate URI into a string and processing it as a string is a reasonable answer to this specific problem. In fact, this particular query can be answered efficiently by a triple store because most triple stores index predicates in an ordered index such that looking up the predicates that start with a certain prefix is fast.
The trouble, however, is that if you want to do a more complex query, such as one that involves both the value of Healthcare_Provider_Taxonomy_Code_N and Healthcare_Provider_Primary_Taxonomy_Switch_N, the process of breaking up the predicates into bits and putting them together becomes increasingly complex and error prone, and it becomes all the less likely that the triple store will understand what you're trying to do and be able to answer the query efficiently. This complexity applies also to rules and other code you write to work with the data. (Note that RDFS and OWL, the standard inference languages, are entirely oblivious to the structure of URIs, greatly limiting what you can do with them if your data is incorrectly shaped.)
Data and queries are like two sides of a coin. If we change the shape of the data, that changes the queries we need to write against them. We can often work around a weakness in the data by writing a more complex query, but another answer to to improve the shape of the data, which is what we will do next.