The JSON data format has become a de facto standard for both web services and for document-oriented databases such as MongoDB, CouchDB, OrientDB and Elasticsearch. Programmers like it because it is a good fit for the data structures dynamic languages such as Perl, Python, PHP, and Ruby put on their fingertips. JSON represents a tree structure, just like XML, but with less real (ex. namespaces, the distinction between elements and attributes in XML) and perceived (matching start and end tags in XML) complexity. One feature lost in the name of simplicity was a proper decimal datatype, which is essential for work involving monetary quantities, at least if you want to get the right answer. Support for a full range of primitive data types, including decimal numbers and date and time types, is a major reason why RDF is a "minimal viable" universal data model, and as we'll see in this article, RDF technology lets us "bolt on" a richer set of data types to JSON.
As some would say, money makes the world go round. It's particularly important for banks and other financial institutions, but JSON is used heavily in electronic commerce systems that, hopefully, will get the same numeric results as the bank. (Even the public library charges overdue fines.)
Rather than confront all of the issues, the JSON specfication is cagey about the definition of numbers. The complete specification that it gives is just the format of a text string that encodes a number. The following "railroad diagram", copied from the json.org web site, is the exact definition of the numeric type:
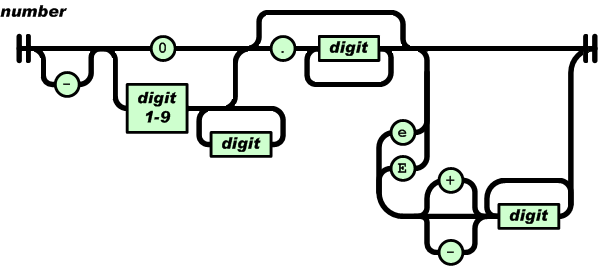
To read this, one starts from the left and works to the right. Starting with an optional minus sign, we find either an series of digits. that begins with a non-zero digit, or that consists only of a zero. This is the whole part of the number. After that, the number can optionally contain a period followed by more digits (the fractional part.) Finally, whether or not there was a fractional part, the number can contain an optional exponents. A few examples would be -7 (a negative integer), 22.4 (a decimal fraction), or 1.7e20 (a large number expressed in scientific notation.)
In most of the places where the production "digit" appears, it is in a loop which does not specify a minimum or maximum number of digits. Thus, it is not specified what the precision of these numbers are; some kind of floating point option seems to be implied by the presence of an exponent. If we look at the official RFC 7159 specification, we see the non-specific "This specification allows implementations to set limits on the range and precision of numbers accepted."
Looking specifically at the Javascript language (which is likely to produce or consume a JSON value, either in a web browser or in an environment like node.js), we see that "According to the ECMAScript standard, there is only one number type: the double-precision 64-bit binary format IEEE 754 value ... There is no specific type for integers." (Source: Mozilla Developer Network) This is consistent with the RFC 7159 specification, which states "Since software that implements IEEE 754-2008 binary64 (double precision) numbers [IEEE754] is generally available and widely used, good interoperability can be achieved by implementations that expect no more precision or range than these provide, in the sense that implementations will approximate JSON numbers within the expected precision."
Even though we usually write IEEE 754 floats in a decimal format, as described above, traditional floating point numbers are binary floating point numbers. That is, both the significand and the exponent are written as binary numbers, and the base of the exponent is in base 2 instead of base 10. Thus instead of representing something like 1x1012 directly, the computer encodes something closer to 1x240.
This is quite unfortunate, because binary floating point numbers are a poor choice for monetary quantities. If you use floating point numbers in operational systems, you will eventually cut somebody a check for the wrong amount. The consequences of using floating point for analytics are less direct, but every bit as serious. Specialists, such as accountants and quantitative marketers, have their own ways of knowing that "the figures add up" and if they don't, they won't listen to excuses about why they don't. Bad figures that make it all the way to an annual report can result in an restatement of financial reports that in turn creates extreme pain for investors and management.
In the rest of this chapter, I'll explain exactly why binary floating point numbers are inappropriate for monetary calculations and present some alternatives, particularly the xsd:decimal type which is supported in RDF and SPARQL.

The major reason why you shouldn't use floating point to represent money quantities is that: (i) the U.S. dollar is divided into dimes (1/10 of a dollar) and pennies (1/100 of a dollar) and (ii) the fractions 1/10 and 1/100 do not exist in computer representations of binary math.
We wouldn't have this problem if we simply divided the dollar into halves, quarters, or eigths, like the old Spanish dollar pictured above. In fact, if we had 128 "cents" in a dollar, or some other power of two, we'd be able to represent money quantities exactly. However, when we do math in base N, we can only represent fractions where the denominator contains only factors that exist in N. The number 10 has 2 and 5 as factors, so we can exactly write 1/2=0.5, 1/4=0.25, 1/8=0.125, 1/5=0.2, and 1/10=0.1. If we wanted to write 1/3, however, we get a repeating decimal, 1/3=0.333333, or just 0.3 where the overline indicates that the 3 repeats forever. If we truncate the number at any particular place, we get an answer that is an approximation, and not exact.
It's not too different in binary, except the denominator of the fraction can only contain factors of two, such as 1/2=0.1b, 1/4=0.01b, 1/8=0.001b, etc. If you want to write 1/10, however, you end up with a repeating number: 1/10=0.00011b. If you truncate this in some particular place, you'll introduce errors that you can't entirely sweep under the rug. An example of a wrong result can be seen in the following Python session:
Python 2.7.6 (default, Oct 26 2016, 20:30:19)
[GCC 4.8.4] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> 0.3+0.6
0.8999999999999999
>>> 0.9
0.9
>>> (0.3+0.6)==0.9
False
>>> 0.9==0.9
True
Two bad things happen: (i) we get 0.8999999999999999 instead of the expected 0.9, and (ii) if we ask explicitly, we find the result is not equal to 0.9. Thus, it's not safe to test floating point numbers for equality, and the best we can do is check that the difference between two numbers is below some threshold. With some effort to deal with this weirdness, floating point is acceptable for scientific and engineering calculations, but it's a recipe for trouble to use it when money is involved, adding to the many the mistakes that run of the mill programmers make.
Notes: (1) This is not a Python problem. We'd get the same results if we used Java, Javascript, C, R, or any other language that uses IEEE 754 floats. (2) Microsoft's Excel spreadsheet uses the same IEEE 754 floats as most other tools, but a cell with the formula =0.3+0.6 displays as 0.9 because it uses some sketchy display conventions to hide the discrepencies. (3) Although currencies differ, the US dollar is not the only currency which is subdivided. Although the Japanese Yen has not been subdivided since 1953, the Euro, UK Pound and the Mexican Peso are all divided into units of 100 cents (or centimos). Prior to 1971, the Pound was divided into 240 pence, requiring the representation of powers of three in the denominator, as well as of two and five. (4) Yes, we could represent dollar quantities in cents, so long as we never forget the factor of 100, in which case we'll really write a check for the wrong amount.
Fortunately, there are correct data types for dealing with money. In Java, for instance, there is the BigDecimal type, while Python has the decimal module, PHP has the optional BCMath BCMath module, and so forth. The SQL specification has a DECIMAL(p,s) datatype where p is the precision, the total number of binary digits, and s is the scale, the number of digits right of the decimal point. (This is supported in most SQL implementations such as MySQL, PostgreSQL and Microsoft SQL Server.)
The good news is that RDF, and by extension, SPARQL databases, support the xsd:decimal type which is defined in the XML Schema Datatypes specification. In the Turtle language, this is written like
@prefix : <http://example.com/>.
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
[
a :Product ;
:SKU "B7641" ;
:price "19.99"^^xsd:decimal ;
]
In RDF, a literal is written as the product of two things: (i) a lexical form ("19.99") and (2) a datatype, in this case given by the URI <http://www.w3.org/2001/XMLSchema#decimal>. RDF tools then map the xsd:decimal datatype to some local datatype. In the case of Java, the decimal is mapped to new BigDecimal("19.99").
JSON-LD, as a way to write RDF in JSON, provides a simple and backward-compatible path to write xsd:decimal and other missing types. If we're writing "new" JSON-LD documents, it is possible to specify the lexical form and data type as a pair, just as we do in Turtle:
{
"@context": {
"@vocab": "http://example.com/"
},
"price": {
"@value": "19.99",
"@type": "http://www.w3.org/2001/XMLSchema#decimal"
}
} Note that by simply specifying a default vocabulary with @vocab the JSON-LD processor knows that the "price" key is mapped to the <http://example.com/price> predicate. An RDF Literal can then be written as a @value, @type pair. This style is backwards compatible with conventional JSON processors, in the sense that the type information is passed through losslessly, but could be just a little awkward to process with tools that aren't aware of JSON-LD because we're replacing what would be a simple value with @value, @type pair.
Fortunately, JSON-LD offers us another option, which is to specify which datatype is expected for a particular JSON key.
{
"@context": {
"price": {
"@id": "http://example.com/price",
"@type": "http://www.w3.org/2001/XMLSchema#decimal"
}
},
"price": "19.99"
}The @context is a recipe for how to convert a JSON document into RDF facts. Here the key "price" is associated with a particular RDF predicate and with a particular datatype. This paints a new meaning on what would otherwise be just the text string "19.99"; to ordinary JSON tools it is just a character string, transmitted without loss. The @context lets tools aware of JSON-LD know that this field has a special meaning, and needs to be interpreted as an instance of an arbitrary data type.
In the above example, the @context is built into the JSON document, but it can equally be specified by a link to an external context, an http header, or injected as a default at the time of processing. Thus with very little ceremony, we can (i) give an RDF meaning to JSON documents created without RDF in mind, and (ii) add the few features that JSON needs to become a more universal data model.
JSON is a popular data model, rightfully so, because it is a simple representation for the hierarchical structures that occur in many programs, particularly those that are organized on an object-oriented basis. JSON can be thought of as a "simpler XML", which strips away a number of features that make XML more difficult to work with. For a universal data model, however, JSON is a little bit too simple in a few ways, particularly that it lacks essential primitive types such as dates, times, and a decimal data type which is appropriate for monetary calculations.
JSON-LD fills this gap by making it possible to add a few annotations to a JSON document that give JSON the complete expressiveness of RDF, including the XML Schema data types such as xsd:decimal, xsd:date and xsd:datetime. As RDF was originally based on ideas from XML, it's much like JSON-LD adds the missing functionality from XML to JSON -- but with refreshingly little ceremony, since the schema (the JSON-LD context) can be imported from an external file. Thus we can explicitly use JSON-LD to add features to JSON in an API (such as Gmail Markup) or to add meaning to existing JSON formats.
This might be new to developers, who are used to schemas being used to constrain the shape of data (most of XML Schema) or to define how data will be physically stored (in the case of SQL or a Java class definition.) In RDF, however, the primary purpose of schemas is to add meaning to data -- that is, given a document and a schema, we can infer new facts. Although this has some precedent (in XML Schema you can set a default value which infers facts not in the original document), this is the key difference between RDF and previous approaches to data integration. A complete set of primitive types (such as for decimal arithmetic) is foundational for this, since with the right tools for modelling business in place, we can focus on developing applications instead of dealing with errors caused by using the wrong primitives.