
Getting started with the DBpedia SPARQL endpoint¶
In this episode I begin to explore the DBpedia public SPARQL endpoint. I'll go through the following stages
- setting up tools
- counting triples
- counting predicates
- examination of the predicate pr:skipperlastname
- countings classes
- examination of the class on:CareerStation
My method is a deliberate combination of systematic analysis (looking at counts, methods that can applied to arbitrary predicates or classes) and opportunism (looking at topics that catch my eye.) DBpedia is too heterogenous to characterize in one article, but I'll begin to uncover the dark art of writing SPARQL queries against generic databases.
Setting up tools¶
A first step is to import a number of symbols that we'll use to do SPARQL queries and visualize the result
%load_ext autotime
import sys
sys.path.append("../..")
from gastrodon import RemoteEndpoint,QName,ttl,URIRef,inline
import pandas as pd
pd.options.display.width=120
pd.options.display.max_colwidth=100
First I'll define a few prefixes for namespaces that I want to use.
prefixes=inline("""
@prefix : <http://dbpedia.org/resource/> .
@prefix on: <http://dbpedia.org/ontology/> .
@prefix pr: <http://dbpedia.org/property/> .
""").graph
Next I set up a SPARQL endpoint and register the above prefixes so I can use them; it is also important that I set the default graph and base_uri so we'll get good looking short results.
endpoint=RemoteEndpoint(
"http://dbpedia.org/sparql/"
,default_graph="http://dbpedia.org"
,prefixes=prefixes
,base_uri="http://dbpedia.org/resource/"
)
Counting Triples¶
First I count how many triples there are in the main graph
count=endpoint.select("""
SELECT (COUNT(*) AS ?count) { ?s ?p ?o .}
""").at[0,"count"]
count
Counting Predicates¶
For the next query I make a list of common predicates; note that there are a whole lot of them! The public SPARQL endpoint has a limit of 10,000 returned rows and we are finding many more than that.
Each predicate is a relationship between a topic and either another topic or a literal value. For instance, the rdf:type predicate links a topic to another topic representing a class that the first topic is an instance, for instance:
<Alan_Alda> rdf:type on:Person .rdfs:label, on the other hand, links topics to literal values, such as
<Alan_Alda> rdfs:label
"Alan Alda"@en,
"アラン・アルダ"@ja .Strings in RDF (like the one above) are unusual compared to other computer languages because they can contain language tags, a particularly helpful feature for multilingual databases such as DBpedia.
predicates=endpoint.select("""
SELECT ?p (COUNT(*) AS ?count) { ?s ?p ?o .} GROUP BY ?p ORDER BY DESC(?count)
""")
predicates
Some notes.
First of all, properties that are original to DBpedia. are in two namespaces; the on namespace contains DBpedia Ontology properties which are better organized (mapped manually) than the pr namespace that contains properties that are mapped automatically. The select function returns short names for predicates in these namespaces because I specified them in the prefix list above.
DBpedia also uses predicates that are defined in other namespaces, such as foaf and dc. Frequently these duplicate properties that are defined in DBpedia, but facilitate interoperability with tools and data that use standard vocabularies. select would show you short names for these to if I added them to the prefix list, but I didn't, so it doesn't.
If you look closely, you might notice we got exactly 10,000 results from this last query. This is not because DBpedia uses only 10,000 distinct predicates, but because the DBpedia SPARQL endpoint has a 10,000 row result limit. This can be annoying sometimes, but it protects the endpoint from people who write crazy queries. There is a bag of tricks for dealing with this, but in the purposes of this article, 10,000 predicates is enough to get started.
This begs the question:
"How many distinct predicates are used in DBpedia?"
which is easy to answer with a SPARQL query:
endpoint.select("""
SELECT (COUNT(*) AS ?count) { SELECT DISTINCT ?p { ?s ?p ?o .} }
""")
When you have a number of "things" ordered by how prevalent there are, a cumulative distribution function is a great nonparametric method of characterizing the statistics
predicates["dist"]=predicates["count"].cumsum()/count
%matplotlib inline
predicates["dist"].plot()

This distribution certainly looks like it has a "knee" somewhere in the teens, probably involving a transition from predicates that could apply to any topic such as rdfs:comment as opposed to predicates specific to certain subject areas, such as on:team.
predicates["dist"].head(100).plot()

Here are the top 20 predicates, representing more than 80% of the predicates used in the main graph
predicates.head(30)
Looking at the tail, I find some very random sorts of properties.
predicates.tail()
Here are predicates that are at the 90%, 95%, 98%, and 99% cumulative distributions, just to get a sense of what happens as things get more rare.
predicates[predicates["dist"]>0.9].head(1)
predicates[predicates["dist"]>0.95].head(1)
predicates[predicates["dist"]>0.98].head(1)
predicates[predicates["dist"]>0.99].head(1)
pr:skipperlastname (property ranked number 9993) caught my eye, so I take a look at it.
endpoint.select("""
SELECT ?s ?o { ?s pr:skipperlastname ?o }
""")
Looks like it has to do with sailing. It's not an area that I know much about, so I'll transclude the page describing one of the topics from Wikipedia so we can understand it.
from bs4 import BeautifulSoup
from IPython.display import display, HTML
from uritools import urijoin
def transclude(file):
with open(file,"rt",encoding="utf8") as fp:
soop = BeautifulSoup(fp,"html5lib")
for a in soop.find_all("a"):
a["href"]=urijoin("http://en.wikipedia.org/",a["href"])
return HTML(str(soop.body))
transclude("The_Race.html")
The Race (yachting race)
The Race was a round-the-world sailing race starting in Barcelona, Spain on December 31, 2000. It was the first ever non-stop, no-rules, no-limits, round-the-world sailing event, with a $2 million US prize. It was organized by Bruno Peyron.
The stated objectives of this race were:
- to unite the different maritime cultures of the world
- to gather together the world's premiere yachtsmen and women in a common event
- to promote creativity in ocean sailing
- to ally high technology and the environment
- to create the most spectacular and most prestigious fleet of offshore racers that sailing has ever seen
A second race was planned for 2004, but was cancelled amid controversy that Tracy Edwards had organized a competing event called Oryx Quest.
Contents
Results[edit]
The 2000–01 race was won by Club Med, skippered by Grant Dalton in 62d 6h 56' 33".
| Pos | Boat | Crew | Country | Time |
|---|---|---|---|---|
| 1 | Club Med | Dalton, Grant Grant Dalton | 62d 6h 56m 33s | |
| 2 | Innovation Explorer | Peyron, Loick Loick Peyron & Skip Novak | 64d 22h 32m 38s | |
| 3 | Team Adventure | Lewis, Cam Cam Lewis | 82d 20h 21m 02s | |
| 4 | Warta Polpharma | Paszke, Roman Roman Paszke | 99d 12h 31m | |
| 5 | Team Legato | Bullimore, Tony Tony Bullimore | 104d 20h 52m | |
| - | PlayStation | Fossett, Steve Steve Fossett | DNF[a] | |
| - | Team Philips | Goss, Pete Pete Goss | DNS |
- ^ Damaged and forced to withdraw on day 16
Legend: DNF – Did not finish; DNS – Did not start;
That wikipedia page is pretty informative, let's see what facts are in DBpedia concerning "The Race".
Because I set the base_uri when I the endpoint object, DBpedia resources (which largely correspond to Wikipedia pages) can be easily written using angle brackets. It would be tempting to create a namespace for them, but it turns out that SPARQL and Turtle let you write a wider range of characters insides brackets, as opposed to in a namespace. Particularly, the parenthesis in <The_Race_(yachting_race)> are legal, but dbpedia:The_Race_(yachting_race) is not allowed!
pd.options.display.max_rows=99
endpoint.select("""
SELECT ?p ?o {<The_Race_(yachting_race)> ?p ?o }
""")
What's the story here? Cells from the table have been converted into facts, but the order of the facts has been scrambled. We know that one of the boats finished in "5381793.0" seconds, and we know there was a boat named "Warta_Polpharma" and so forth, but we don't know which boats finished, which boats boats finished in what time, which boat had what skipper, etc.
This is not a limitation of RDF, but it is a common limitation of RDF-based systems in the "Linked Data" era, and it's historically been a problem in RDF.
The basic problem is that if we want to write a statement like the one on the first row of the HTML table, we end up having to write something like
<Some_Node>
pr:pos 1 ;
pr:boat <Club_Med> ;
pr:skipper <Grant_Dalton> ;
pr:nation "NZL" ;
pr:time 5381793.0 .
<The_Race_(yaching_race)> pr:entry <Some_Node> .the only hard part is determing a name for <Some_Node>. In the case of DBpedia, names are derived from URIs in Wikipedia, a formula that doesn't apply when we're talking about a concept that doesn't have a URI in Wikipedia. We can duck the problem of assigning a name by using a blank node (which states a node exists without giving a specific name) but that causes problems of its own which come from the difficulty of having something nameless in a distributed system. (What if I want to talk about a nameless entity that exists in DBpedia?)
For specific problems, it's possible, and often straightforward, to find ways to name nodes like <Some_Node>. However, it is hard to find a solution that pleases everybody, particularly when we are talking about a system which is decentralized, in which people would like names to be stable over time, etc.
With conflicting demands, it's no wonder that this area has not been standardized by the W3C, but it's great to see that DBpedia is making some progress in this area, which I'll show in the next section.
Classes¶
Note I started this analysis by looking first at the most commonly used predicates. If I was looking a SQL database, this would be like looking at a list of columns first, and if I was looking at an Object-Oriented program, it would be like looking at a list of methods and fields.
It would be much more common to look at tables first in SQL or classes first in Java, but RDF is different from SQL and Java, and it often makes sense to look at properties first.
For one thing, it is possible to write properties without defining any classes or categories, that is, the RDF statement
<SomeTopic> :hasNumber 1023 .is self-sufficient and meaningful without knowledge that <SomeTopic> is a particular kind of topic. Thus, properties are more fundamental.
More practically, people get into more trouble with classes than they do with properties. Part of it is that people tend to argue more about classes (ex. can a video game be art?) than they do about properties (ex. "Hideo Kojima was thge director of Metal Gear Solid") In the case of DBpedia, one problem is the sheer number of categories:
types=endpoint.select("""
SELECT ?type (COUNT(*) AS ?count) { ?s a ?type .} GROUP BY ?type ORDER BY DESC(?count)
""")
types
endpoint.select("""
SELECT (COUNT(*) AS ?count) { SELECT DISTINCT ?type { ?s a ?type .} }
""")
On average, that's nearly eight classes for every property!
DBpedia, it turns out, contains many types from YAGO, which are in turn generated from Wikipedia Categories and other data sources. Many of these classes such as yago:WikicatPeopleFromYokohama and yago:MexicanMaleFilmActors are classes that are members of very large families that include "People from Lanzarote", "Brazillian female professional wrestlers" as such. Two common patterns are:
- Restriction types: One could name "People from Yokohama" as a class, and ask for instances of that class. Alternatively, one could query for people for whom the property "comes from" has the value "Yokohama". A class whose membership is determined by property values is a "restriction type".
- Intersection types: "Mexican Person" is a class, "Male Person" is a class, "Film Actor" is a class. The set of topics which are members of all of those classes is "Mexican Male Film Actors".
As you can say the same things with or without restriction and intersection types, it is a case-by-case decision as to whether to use them or to compose them from other elements. What is clear, in this type, is that there are so many realized restriction and intersection types from YAGO that it gets in the way of seeing what kind of things are talked about in DBpedia.
An easy "set of blinders" to use here is to look only at types that are in the DBpedia Ontology namespace. Rather than write a new SPARQL query, I use the filtering operator in Pandas to pick out common types from the DBpedia Ontology.
types[types.index.str.startswith('on:')]
on:Image catches my eye, so I look at a few examples and pick one out.
endpoint.select("""
SELECT ?that {
?that a on:Image
} LIMIT 10
""")
HTML('<img src="{0}">'.format(_.at[0,'that']))

These "topics" are what I would call "non-topic topics" in the sense that they are the subject of a statement, but not an actual "thing in the world" described by the knowledge base. (Wikipedia documents the outside world primarily, and only secondarily has a metadata catalog for items that are in it.)
The following query finds "plain ordinary topics"
endpoint.select("""
SELECT ?that {
?that a on:Person
} LIMIT 10
""")
"Andres_Ekberg" is a shorthand for <http://dbpedia.org/resource/Andreas_Ekberg> which is parallel to the Wikipedia page at
<http://en.wikipedia.org/wiki/Andres_Ekberg>. The select() method shows just "Andreas_Ekberg" because I registered <http://dbpedia.org/resource/> as the base URI of this endpoint when I created the endpoint object way back at the beginning of this notebook.
What most people would think of as "topics" in DBpedia live in the <http://dbpedia.org/resource/> namespace.
Another common kind of topic in DBpedia is the on:Agent:
endpoint.select("""
SELECT ?that {
?that a on:Agent
} LIMIT 10
""")
The "Agent" concept is connected with the shared attributes of individuals and organizations; I like to think that an "Agent" is something that can be the originator or recipient of a communication. If I remove people using the MINUS operator, only organizations remain.
endpoint.select("""
SELECT ?that {
?that a on:Agent
MINUS {?that a on:Person}
} LIMIT 10
""")
Unlike the classes I've shown so far, a on:TimePeriod can be either a topic or non-topic. Asking for just 10 time periods, I find that some of them correspond to calendar years:
endpoint.select("""
SELECT ?that {
?that a on:TimePeriod
} LIMIT 10
""")
transclude("1004.html")
If, however, I make a query that eliminates topics that start with a number, the query returns a large number of non-topics. Even though these resources are in the <http://dbpedia.org/resource/> namespace, they don't have corresponding Wikipedia pages.
endpoint.select("""
SELECT ?that {
?that a on:TimePeriod .
FILTER(STRSTARTS(STR(?that),"http://dbpedia.org/resource/A"))
} LIMIT 10
""")
Let's take a closer look. It seems that this record describes a time that a soccer player spent playing for a team (although unfortunately it doesn't say when this time began or ended):
endpoint.select("""
BASE <http://dbpedia.org/resource/>
SELECT ?p ?o {
<Abbie_Wolanow__1> ?p ?o .
}
""")
This record is more complete, and shows how the career record can be linked to a time, as well as information about how the player performed:
endpoint.select("""
BASE <http://dbpedia.org/resource/>
SELECT ?p ?o {
<Abbie_Wolanow__5> ?p ?o .
}
""")
Going to the right of the career station (finding objects for which it is the subject) we see the team, but we don't see the player. Going to the left, however (finding objects for which it is the subject) we see the player.
endpoint.select("""
BASE <http://dbpedia.org/resource/>
SELECT ?s ?p {
?s ?p <Abbie_Wolanow__5> .
}
""")
Thus this fragment of the RDF graph looks like:
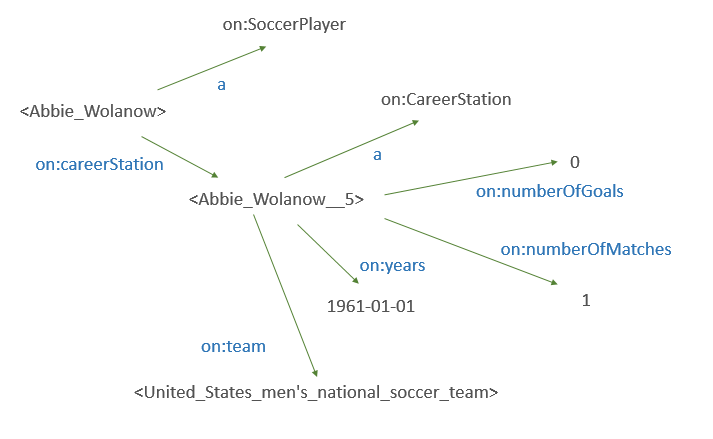
and this a general pattern for how one might deal with situations where we want to say something more complex than "Abbie Wolanow played for the U.S. Men's National Soccer Team".
In terms of the source data, Career stations are much like the race entries in the yachting example in that a single page on Wikipedia contains a number of "sub-topics" that need to be referred to in order to keep together facts such as "this boat was the third finisher" and "Cam Lewis was the skipper of this boat"
The difference is that DBpedia identifies individual career stations while it does not indentify individual race entries.
Here is a survey of the different predicate types that are used to describe career stations. I was probably a bit unlucky to pick a player who didn't have on:years specified very often:
endpoint.select("""
SELECT ?p (COUNT(*) AS ?count) {
?that a on:CareerStation .
?that ?p ?o .
} GROUP BY ?p ORDER BY DESC(?count)
""")
What sort of people have career stations? I count the career stations and get the following results:
pd.options.display.max_rows=20
has_cs_types=endpoint.select("""
SELECT ?type (COUNT(*) AS ?count) {
?station a on:CareerStation .
?who on:careerStation ?station .
?who a ?type .
} GROUP BY ?type ORDER BY DESC(?count)
""")
has_cs_types[has_cs_types.index.str.startswith("on:")]
Career stations seem heavily weighted towards people who play soccer! The numbers above are hard to compare to other characteristics, however, because they are counting the career stations instead of the people. For instance, Abbie Wolanow is counted five times because he has five career stations.
With a slightly different query, I can count the actual number of people of various types who have career stations.
has_cs_types=endpoint.select("""
SELECT ?type (COUNT(*) AS ?count) {
{ SELECT DISTINCT ?who {
?station a on:CareerStation .
?who on:careerStation ?station .
} }
?who a ?type .
} GROUP BY ?type ORDER BY DESC(?count)
""")
has_cs_types[has_cs_types.index.str.startswith("on:")]
Note that the counts here do not need to add up to anything in particular, because it is possible for someone to be in more than one category at a time. For instance, we see the same count for on:Person and on:Agent as well as on:Athlete and on:SoccerPlayer because each soccer player is an athlete. I got suspicious, however, and found that if I added the number of soccer players to the number of soccer managers...
18617+117270
... and found they were equal! That suggests that all of the people with career stations are involved with soccer, and that on:SoccerPlayer and on:SoccerManager are mutually exclusive.
I test that mutually exclusive bit by counting the number of topics which are both soccer players and soccer managers:
endpoint.select("""
SELECT (COUNT(*) AS ?count) {
?x a on:SoccerPlayer .
?x a on:SoccerManager .
}
""")
Those two really are mutually exclusive.
This seems strange to me. I don't know much about soccer (I am from the U.S. after all!) but frequently coaches and team managers are former players in other sports, shoudn't they be in soccer?
I investigate just a bit more, first getting a sample of managers...
endpoint.select("""
SELECT ?x {
?x a on:SoccerManager .
} LIMIT 10
""")
... and then looking at the text description of one in particular:
endpoint.select("""
SELECT ?comment {
<http://dbpedia.org/resource/Alex_Ferguson> rdfs:comment ?comment .
FILTER(LANG(?comment)='en')
}
""").at[0,"comment"]
As I suspected, Alex Ferguson was a player who became a manager. These things are not mutually exclusive in the real world, although they are mutually exclusive in DBpedia.
It's a typical example of what you find when you look at "how things are" as opposed to "how things are supposed to be".
If it were up to me you'd be a soccer player if you'd ever played soccer and you'd be a manager if you'd ever managed a soccer team. On the other hand, I don't have my own database of thousands of soccer players (and managers!) so having to accept data in the format it is provided in is part of the price of "free" data.
Conclusion¶
In this article I began an investigation of data in DBpedia that particularly focused on two kinds of topics: race entries and the careers of soccer players. In the first case, information about different entries in the race are scrambled, because no subject is introduced for each entry. In the second case, DBpedia provides identifiers for "Career Stations" upon which it can state facts such as what team a person played on, for what time period, and so forth.
I hope very much that the "Career Station" is the future of DBpedia because there are many other things that can be modeled very similarly such as:
- a person's educational career
- the work career of a person who works for multiple employers over time
- times in which a person has been a member of a band
- locations of a concert tour
- results of a series of sports events
Introduced in DBpedia 3.9, "Career Station" is relatively new. Other generic databases such as Freebase and Wikidata have used mechanisms such as compound value types and qualifiers to similar effect. Let's hope that the enthusiasm soccer fans have brought to DBpedia will carry over to other sports and endeavors!

|
This article is part of a series. Subscribe to my mailing list to be notified when new installments come out. |