
Inference Over RDF Containers¶
Introduction¶
In a previous notebook, I demonstrated queries and operations over RDF Containers, one of two ways to represent ordered lists in RDF.
This work is motivated by my analysis of XMP data found on my computer. XMP data uses Containers heavily, so I need ways to work with them that roll off my fingers. I felt the queries in the last notebook were a little more complex than they needed to be, so in this notebook I explore the use of inference to simplify queries and show a set of example queries that illustrate patterns for making queries against RDF Containers.
Inference is, at root, a simple concept. Given some set of facts, we can infer more facts. In the case of RDF Containers, we might have the fact that
?list rdf:_7 ?member .and can infer that
?list rdfs:member ?member .This makes it easy to write a query such as "what lists is ?member a ?member of". This particular example is simple and mechanical, but more complex inference rules are used in business rules engines to answer questions such as "can we ship this product to that customer?" or "will we extend credit to this customer?"
This notebook works an example end to end, including
- how to write queries over RDF Containers without inference
- two inference rules that simplify queries over RDF Containers
- a simple inference engine based on SPARQL
- a discussion of more complex inference engine
- a cookbook of queries over RDF Containers
Setup¶
Here I import the libraries that I use and configure Pandas.
%load_ext autotime
import sys
sys.path.append("../..")
from gastrodon import *
from rdflib import *
import pandas as pd
pd.options.display.width=120
pd.options.display.max_colwidth=100
A Day at the races¶
Next I load a small data set to run test queries against:
races=inline(r"""
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix : <http://example.com/> .
:tioga_downs_2017_08_14
a rdf:Seq ;
rdf:_1 :race_1 ;
rdf:_2 :race_2 ;
rdf:_3 :race_3 .
:race_1
a rdf:Seq ;
rdf:_1 "PRINCE ADIRAN" ;
rdf:_2 "KDMAKEWAY" ;
rdf:_3 "ANDERSON VALLEY" ;
rdf:_4 "SETTINEMONFIRE" ;
rdf:_5 "TRILLIONAIR" ;
rdf:_6 "OZZY BLUE CHIP" .
:race_2
a rdf:Seq ;
rdf:_1 "MACHMEMACKIE" ;
rdf:_2 "FREE LOVE" ;
rdf:_3 "FRANKIES DRAGON" ;
rdf:_4 "IM AN ART MAJOR" ;
rdf:_5 "GOLD STAR SPIKE" ;
rdf:_6 "F TWENTY TWO" ;
rdf:_7 "TAILGUNNER HANOVER".
:race_3 ;
a rdf:Seq ;
rdf:_1 "LYONS JOHNNY" ;
rdf:_2 "BETTORSLUCKYSTREAK" ;
rdf:_3 "DASH OF DANGER" ;
rdf:_4 "NEPTUNE" ;
rdf:_5 "WINYARD HANOVER" ;
rdf:_6 "DEE'S ROCKETMAN" .
""")
These come from the race results on August 14, 2017 at the Tioga Downs harness racing track. This is not an example of a great RDF representation of this kind of data, but data structures like this are often used in scripty programs written in languages such as Python and Lisp. If you want to imagine what a better representation looks like, take a look at the source material:
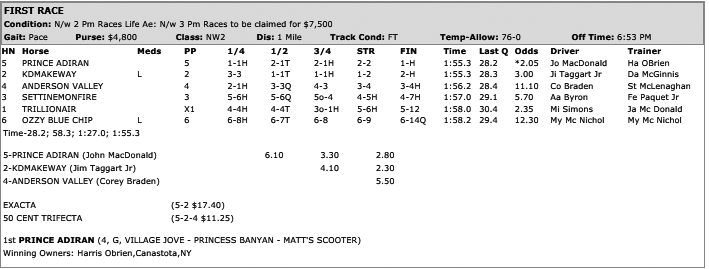
Queries without inference¶
Suppose we wanted to get a list of all race entries in all races. The following query does the trick:
races.select("""
SELECT ?horse {
:tioga_downs_2017_08_14 ?p1 ?race .
?race ?p2 ?horse .
FILTER(STRSTARTS(STR(?p1),"http://www.w3.org/1999/02/22-rdf-syntax-ns#_"))
FILTER(STRSTARTS(STR(?p2),"http://www.w3.org/1999/02/22-rdf-syntax-ns#_"))
}
""")
There are two things that bother me about this query:
- It has a long, arbitrary-looking, hard to remember, and error prone FILTER clause for each container I want to traverse (what if I cut and pasted it and it was
?p1both times) - It is not so obvious in this query, but FILTER statements can occur only after all of the "basic graph patterns" (ex.
?s ?p ?o .) so the FILTER statements may have to be far away from the predicates they control, making complex queries all the more complex and mysterious
The good news is that the RDF Schema specification already specifies a few inference rules to simplify this kind of query:
What is inference?¶
RDF Inference is a process in which we have some facts, and then apply some rules to those facts to get more facts. Inference addresses some of the problems solved by triggers and views in relational databases. Inference is implemented in two ways:
- In the case of Forward Chaining, we compute the new facts and insert them in the database so that they will be seen by the query procedure. (This is like a trigger in SQL)
- In the case of Backward Chaining we rewrite the query or change the query answering procedure so that the new facts appear to be there. (This is like a view in SQL)
RDFS Schema contains a number of features that are implemented with rules. Often we're not interested in all of the possible inferences, in which case we can implement the rules with a simple "inference engine" we write ourselves.
rdfs:ContainerMembershipProperty¶
The ContainerMembershipProperty class provides a quick way to select any predicate which denotes membership in a container. According to the standard,
The rdfs:ContainerMembershipProperty class has as
instances
the properties rdf:_1, rdf:_2, rdf:_3 ... that are
used to state
that a resource is a member of a container.
rdfs:ContainerMembershipProperty is a subclass
of rdf:Property. Each
instance of
rdfs:ContainerMembershipProperty is an rdfs:subPropertyOf
the rdfs:member property.
Given a container C, a triple of the form:
C rdf:_nnn O
where nnn is the decimal representation of an integer
greater than 0 with
no leading zeros, states that O is a member of the container C.
Container membership properties may be applied to resources other than containers.
The term rdfs:subPropertyOf is important in the above definition and is defined as follows:
The property rdfs:subPropertyOf is an instance of rdf:Property that is used to state
that all resources related by one property are also related by
another.
A triple of the form:
P1 rdfs:subPropertyOf P2
states that P1 is an instance of rdf:Property,
P2 is an instance of rdf:Property
and P1 is a subproperty of P2. The
rdfs:subPropertyOf property is transitive.
The rdfs:domain of
rdfs:subPropertyOf is rdf:Property.
The rdfs:range of
rdfs:subPropertyOf is rdf:Property.
Putting together the two definitions and thinking about it, I get the idea that we can implement ContainerMembershipProperty by
writing the following production rule in psuedocode, where I use regular expression symbols to formalize the rdf:_nnn idea in
the definition above.
IF
?s ?p ?o .
AND ?p MATCHES :rdf_[1-9]([0-9])*
THEN
?p a :ContainerMembershipPropertyThere is not a well-standardized way to write production rules in RDF, but we can easily write a SPARQL query that implements this, at the cost of reversing the order of the IF and THEN clauses:
def rule_1(endpoint):
endpoint.update("""
INSERT {
?p a rdfs:ContainerMembershipProperty .
} WHERE {
?s ?p ?o .
FILTER(REGEX(STR(?p),"^http://www[.]w3[.]org/1999/02/22-rdf-syntax-ns#_[1-9]([0-9])*$"))
}
""")
rule_1(races)
To see what this entails, I run the following query:
races.select("""
SELECT ?p {
?p a rdfs:ContainerMembershipProperty .
} ORDER BY ?p
""")
And I can now write a query for "all race entries" that is a little more sensible:
races.select("""
SELECT ?horse {
:tioga_downs_2017_08_14 ?p1 ?race .
?p1 a rdfs:ContainerMembershipProperty .
?race ?p2 ?horse .
?p2 a rdfs:ContainerMembershipProperty .
}
""")
Let's talk about entailment¶
Here's an issue which may seem a little strange, but it is fundamental to the use of logic to solve problems in computing.
We know, for instance, that
rdf:_179426083 a rdfs:ContainerMembershipProperty .and this is true for every integer greater than zero, that is, one way of thinking about it, the ContainerMembershipProperty entails an infinite number of facts!
It's not at all conceivable that we could materialize an infinite number of facts if we were forward chaining. It would not only take an infinite amount of time, but it would take an infinite amount of space.
What's less obvious is that if we implemented the ContainerMembershipProperty rule inside the SPARQL engine, it is just as unreasonable to generate an infinite number of rows by writing a query like
SELECT ?p {
?p a rdfs:ContainerMembershipProperty .
} ORDER BY ?peven though this looks much like writing
count=0
while True:
print(count)
count+=1in Python, which is possible, if ill-advised. (There is a reason why I am embedding that code in a Markdown block instead of running it in a code block!)
It turns out that SPARQL, SQL and most other query languages only allow bounded loops, so that it is impossible to write a program that runs forever. This is opposed to a Turing-complete language such as Python in which one can write more expressive programs at the cost of possibly writing a program which never terminates. (See the Halting Problem if you wish to learn more.)
This kind of issue is addressed by defining an entailment regime; for instance, to answer any query where
?p a rdfs:ContainerMembershipProperty .has a ?p that matches a resource in a query pattern, we only need to materialize those facts for predicates that actually occur in the graph, as opposed to those which could match any possible statement.
rdfs:member¶
The rdfs:member property connects each container to all of its members. It is defined like so:
rdfs:member is an instance of rdf:Property
that is a super-property of all
the container membership properties i.e. each container membership
property
has an rdfs:subPropertyOf
relationship to the property rdfs:member.
I can implement that rule with the following SPARQL query
def rule_2(endpoint):
endpoint.update("""
INSERT {
?container rdfs:member ?member .
} WHERE {
?container ?containerMembershipProperty ?member .
?containerMembershipProperty a rdfs:ContainerMembershipProperty .
}
""")
rule_2(races)
Then I can write a very simple query that finds all of the non-empty containers in the graph
races.select("""
SELECT DISTINCT ?list {
?list rdfs:member ?member .
}
""")
def container_inference(endpoint):
rule_1(endpoint)
rule_2(endpoint)
This inference engine works because that:
- A fact generated by either
rule1orrule2cannot change the result ofrule1 - A fact generated by either
rule2cannot change the result ofrule2
Thus I can evaluate the rules in sequence and know that I am done. Also the relationship between the rules is simple, so it's easy for me to figure out the right order to evaluate them in.
If I add some facts to the graph, run the engine, add some more facts, and run the engine again, that is also OK, because the act of adding facts to the graph is idempotent.
The Fixed Point Algorithm¶
What I'm doing is closely related to SPIN rules, in fact, SPIN rules are a set of SPARQL update statements that are repeated over and over again until the graph stops changing.
In the case above, for instance, if I got the order of the rules wrong, repeating the inference process to a fixed point would give the same answer as the rules below. It might take a little more time, but the rule author doesn't need to think so much.
Another case for the fixed point algorithm is a rule like:
def rule_t(endpoint):
endpoint.update("""
INSERT {
?self rdfs:subClassOf ?grandparent .
} WHERE {
?self rdfs:subClassOf ?parent .
?parent rdfs:subClassOf ?grandparent .
}
""")
which makes rdfs:subClassOf a transitive property. Because it generates new rdfs:subClassOf statements, running the rule again can generate more facts. It never makes an infinite loop however, since it is triggered by a finite number of statements in the graph. Even if I abuse it by making the graph have a cycle, the iteration stops because, after a while, the rule is inserting the same facts into the graph over and over again, which is a non-operation.
RETE and friends¶
In the case of the simple inference engine, I can work out in my head which rules can cause which other rules to fire, thus put them in the right order.
The RETE algorithm, and variations of the RETE algorithm, does this automatically, compiling a network of matching conditions that could apply to incoming facts, thus only checking the rules that have a chance to fire.
A few examples of RETE-related rules engines are
RETE engines are particularly good for complex event processing and workflow engines workflow as the RETE engine works incrementally, firing rules as they become applicable. Thus the rules can be as valuable for the side effects they generate as they are for the facts they imply.
Truth Maintainance¶
With the container_inference procedure there would be a problem if I deleted facts from the graph, because the system would not know it is supposed to delete rdfs:member statements that were implied by the deleted facts. In this case the problem is solved because I insert the data, do the inference, make queries and never delete any statements.
Really advanced rules engines (many of the ones listed above) combine the RETE algorithm with a Truth Maintainance System which automatically retracts inferred statements when the facts that imply them are removed.
Backwards chaining¶
It is also possible to perform inference by backwards chaining, when you start with a query you'd like to solve, and the query processing engine executes the query to pretend that the inferred facts exist. Prolog is an example of a logic programming language based on backwards chaining. Datalog is a subset of Prolog that applies to database systems, because, like a SPARQL query, Datalog programs are guaranteed to terminate.
In the case discussed here, rdfs:member and rdfs:ContainerMembershipProperty could be implemented in a SPARQL query by rewriting a query like
SELECT ?p {
?p a rdfs:ContainerMembershipProperty .
}to
SELECT ?p {
?s ?p ?o .
FILTER(REGEX(STR(?p),"^http://www[.]w3[.]org/1999/02/22-rdf-syntax-ns#_[1-9]([0-9])*$"))
}and this would be an example of backwards chaining inference. Both RDFS and OWL are designed such that most rule sets can be executed efficiently by either backwards or forward chaining.
Queries over Containers with Inference¶
Counting unique members¶
A count of unique members can easily be made with the following query:
races.select("""
select (count(*) as ?count) {
:race_2 rdfs:member ?member
}
""")
note that this a count of unique members as opposed to a count of members. This can be seen with the following test data:
duplicates=inline(r"""
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix : <http://example.com/> .
:three_cheers
a rdf:Seq ;
rdf:_1 "cheer!" ;
rdf:_2 "cheer!" ;
rdf:_3 "cheer!" .
""")
container_inference(duplicates)
duplicates.select("""
select (count(*) as ?count) {
:three_cheers rdfs:member ?member
}
""")
What happened here is that the facts in an RDF graph have set semantics, so the fact
:three_cheers rdfs:member ?member .
only occurs once, no matter how many container membership properties link those two facts:
duplicates.select("""
select ?s ?p ?o {
?s ?p ?o .
FILTER(?p=rdfs:member)
}
""")
Counting all members¶
it takes a slightly different query to count all members:
duplicates.select("""
select (count(*) as ?count) {
:three_cheers ?p ?member .
?p a rdfs:ContainerMembershipProperty
}
""")
races.select("""
select (count(*) as ?count) {
:race_2 ?p ?member .
?p a rdfs:ContainerMembershipProperty
}
""")
Queries involving property paths¶
Container membership inference helps us take advantage of property paths in SPARQL to simplify queries. For example, consider:
races.select("""
select ?horse {
:tioga_downs_2017_08_14 rdfs:member/rdfs:member ?horse
}
""")
to get a list of all unique horses that ran. This is the same as "all race entries" because a specific horse runs at most once a day.
Fourth horse in the third race?¶
Property paths are just peachy for the case where we want to index specific nested members
races.select("""
select ?horse {
:tioga_downs_2017_08_14 rdf:_3/rdf:_4 ?horse .
}
""")
Queries involving inverse property paths¶
This query takes advantage of ^ reversing the direction of a property in a property path to get "horses that ran in the same race as F TWENTY TWO"
races.select("""
select ?horse {
"F TWENTY TWO" ^rdfs:member/rdfs:member ?horse
}
""")
Queries with variable-length property paths¶
We can recursively descend through members of a list like so:
races.select("""
select ?member {
:tioga_downs_2017_08_14 rdfs:member+ ?member
}
""")
This gives us the members of :tioga_downs_2017_08_14; all of those are lists, so we also get the members of those lists.
another shorthand for paths¶
Steps of property paths have to be literal URIs, not variables. Paths involving variables can be written with the [ ] shorthand. The following query counts all of the race entries, which is the same as the number of horses in this case:
races.select("""
select (COUNT(*) AS ?count) {
:tioga_downs_2017_08_14 ?p1 [ ?p2 ?horse] .
?p1 a rdfs:ContainerMembershipProperty.
?p2 a rdfs:ContainerMembershipProperty .
}
""")
Who finished in the money?¶
In this case, the inverse property path makes for a short and sweet query
races.select("""
select ?race ?win ?place ?show {
?race
^rdfs:member :tioga_downs_2017_08_14 ;
rdf:_1 ?win ;
rdf:_2 ?place ;
rdf:_3 ?show .
}
""")
Distinct counts (for a set of Containers)¶
GROUP BY can be used to count over more than one container. The following counts distinct members:
duplicates.select("""
select ?list (count(*) as ?count) {
?list rdfs:member ?member.
} GROUP BY ?list
""")
In the above case there is one result because there is just one container, but if there are multiple containers, this pattern gives multiple results:
races.select("""
select ?race (count(*) as ?count) {
?race
^rdfs:member :tioga_downs_2017_08_14 ;
rdfs:member ?horse
} GROUP BY ?race
""")
List of (not) distinct counts¶
If the members of the container are not unique, some occur multiple times, and the count of members is greater than the distinct member count. This query counts multiple occurences of members.
duplicates.select("""
select ?list (count(*) as ?count) {
?list ?p ?member.
?p a rdfs:ContainerMembershipProperty .
} GROUP BY ?list
""")
races.select("""
select ?race (count(*) as ?count) {
?race
^rdfs:member :tioga_downs_2017_08_14 ;
?rdfN ?horse .
?rdfN a rdfs:ContainerMembershipProperty .
} GROUP BY ?race
""")
Find containers with a certain number of distinct members¶
This query involves a subquery. Subqueries in SPARQL are very general; most queries you can imagine can be done with subqueries in SPARQL.
This example is simple, using the subquery mechanism to accomplish something like the HAVING clause in SQL. I put the query immediately above into another query which filters for a containers of length 6.
races.select("""
select ?race {
{
select ?race (count(*) as ?count) {
?race
^rdfs:member :tioga_downs_2017_08_14 ;
?rdfN ?horse .
?rdfN a rdfs:ContainerMembershipProperty .
} GROUP BY ?race
}
FILTER(?count=6)
}
""")
Counting with a subquery¶
Some people might find the "list of counts" examples to be awkward because what is done in one place in many programming languages (ex. Python)
len(some_list)as opposed to (1) an aggregate operation in the select clause of the query, (2) a pattern involving rdfs:member or rdfs:ContainerMembershipProperty) and (3) a GROUP BY clause. A subquery can bring these elements closer together, like so:
races.select("""
select ?race ?length {
:tioga_downs_2017_08_14 rdfs:member ?race .
{
select (count(*) as ?length) {
?race rdfs:member ?horse
}
}
}
""")
Here the subquery
{
select (count(*) as ?length) {
?race rdfs:member ?horse
}
}works much like the len() function in Python, and could be reused, like a macro, as part of a more complex query wherever one wishes to compute a distinct count.
Conclusion¶
SPARQL does not provide the typical functions for ordered collections, such as counting the members (counting or not counting duplicates.) Fortunately, the implementation of RDF Containers is conceptually simple and it is possible to implement those functions based on first principles. However, this is one of the things you don't want to think about each time you write a query. This article proposes two answers that work together to make queries against containers easier:
- A partial implementation of RDFS inference that simplifies queries over containers (and)
- A set of sample queries that explores the landscape and offers a set of patterns that can be used to write common (and not so common) queries
As such, it develops a completely transparent case of an RDF inference engine that assists the query writer, illustrating the value of RDF inference.