It's tough to define intelligence, but one kind that we treasure is a "quick learner" who learns to act appropriate to context: who seems to be present, and mentallty there, sharing an experience with you.
A television performer is expected to quickly get the hang of the technical apparatus, to know their lines ahead of time -- to do what the director needs them to do without an excess amount of corrections and expanations. A performer must understand the context and behave appropriately.
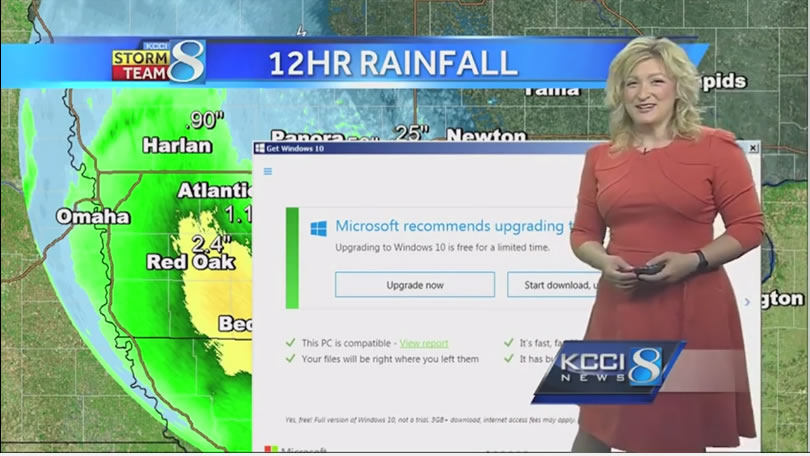
Microsoft Windows 10 failed to do this on the KCCI 8 Television news out of De Moines, Iowa one night when Metinka Slater was doing a weather telecast:
Metinka Slater from De Moines IA had an awkward moment when an annoying pop-up message appeared on the background behind her:
I think most of us have trouble with annoying pop-ups from time to time -- these things that make us feel out of control of our machinery. These things also limit the perceived intelligence of our software, and are necessary if we're going to let automated systems "off the leash" without the fear of embarassment.
The stories we tell around A.I. often center around bizzare, sometimes anthropomorphizable, mistakes made by systems such as IBM Watson, Google Translate, Siri, and many others. We all make mistakes, but some mistakes are worse than others, and most importantly, we need to characterize and eliminate critical errors that have an outsized effect on our perception of quality
Often these concerns get labeled as a "non-functional requirement", an excuse for why we don't need to deal with them, yet, commercial viability of a product hinges on the ability to fix random embarassing errors quickly. For instance, Google's image tagging facility for Android made a mistake that perceived as a racist slur:
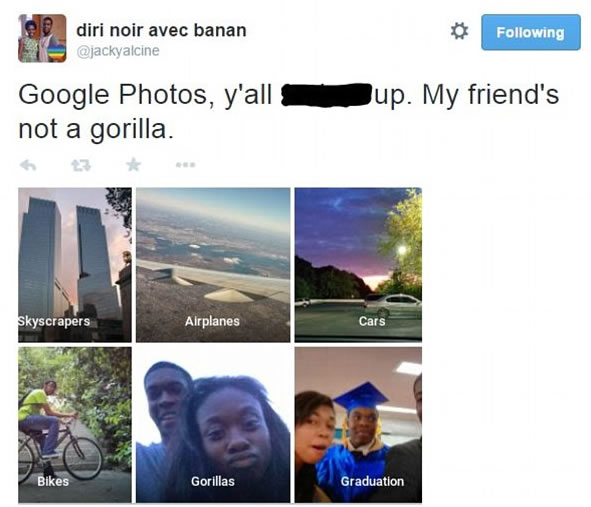
You wouldn't tolerate this from an employee, and you can't tolerate this from a machine.
This mistake happens far fewer than 1 in 10,000 times, and probably isn't going to appear in a test set until long after people complain. Management can't expect to catch every offensive result ahead of time, but it does need a way to fix specific examples that come up, and proactively do something about similar cases that are easy to find. Looking at the results carefully, you could question whether "airplanes" and "cars" are the best labels for some of those images, and may matter very little if the system is 98 or 99% accurate by certain metrics, but certain mistakes are worse than other mistakes, they are critical errors, because they have an impact that can make the system unusable.
In a case like that, the quick fix could be "don't tag anything as a Gorilla", next do a sweep for potentially offensive tags, shut them down at first, and then turn them back on with improved selectivity in the future if that is feasible. The key thing is being able to make the change instantaneously, without a lot of drama. This is a particular challenge for "big data" systems where the core of the model could be a massive neural network that takes days to update on a large cluster -- it's important to be able to make changes based on business requirements right away.
(Steven Levy, in his book, In the Plex, describes a similar situation that was an existential threat to Google in the first few years -- back in the day, you'd often get pornography mixed in with your search results, and getting them out was essential to produce a product that would be safe for advertising. The notorious Matt Cutts, later of web spam fame, earned fame for discovering a creative method to produce training examples.)
You can see that this is deadly for the emerging "internet of things"; you might want the system to "close the blinds when the sun shines in the living room" or "turn on the television and set the Receiver to HDMI 3 when I turn on the Blu-Ray player" but the problem of matching all the different inputs and outputs of the hardware with what a user wants is currently solved by old fashioned computer programming, which takes special skills, is error prone, andrequires constant maintainance as the world changes.
One answer is to throw hardware at the problem. The Kinect controller for the XBOX ONE, for instance, contains a 3-d camera that measures the range to each pixel in an image, which helps a robot understand what it is looking at. (We can think of the XBOX as a sessile robot, which doesn't move around, but is aware of what the user is doing in space.) The Kinect not only tracks your location in space, but it uses a directional microphone array to pick out your voice.

On paper the XBOX ONE Kinect is much better than the XBOX 360 Kinect, but practically, it is another system that "almost works;" Microsoft originally had the Kinect be a required part of the XBOX ONE, but it performed so poorly in the field that Microsoft removed the expensive component. It's kinda fun to tell your game console what to you want to do by speaking to it, yet, the console often misunderstands what you say -- since it doesn't engage you in a real conversation to really understand what you said, sooner or later you get tired of it as it is easier to control the console with an ordinary game controller.
Although speech recognition has vastly improved since the 1980s, it is one of those A.I. technologies that always comes across as a "has been" precisely because of the paradigm behind it. Academics and commercial companies train speech recognition systems against large corpuses of recorded speech correlated with text. On these metrics, voice recognition systems perform better than humans. Superhuman isn't good enough, however, because humans can engage you in a conversation, while current speech recognition systerms can't. It's particularly hard to fit this into the dominant approach, where scientists and engineers compete to get the best results on a fixed data set, because in such a highly interactive system, it's impossible to create a fixed test set which is representative of what could happen. Thus, speech recognition seems to be like the flying cars from the Jetson, always a bridesmaid, never a bride, occasionally supporting a real application in some limited domain, but barely competitive with conventional interfaces and never quite revolutionary.
One application that I've badly wanted for years, that would obviously be useful for search relevance, document organization, and many other tasks, would be a system to extract the meaning of phrases in documents that describe concepts and named entities. I've been following DBpedia spotlight for years, I've contributed bug fixes, and since they've greatly improved their product. It's not that bad (superficially)when we set the confidence to 0.5 for this document:
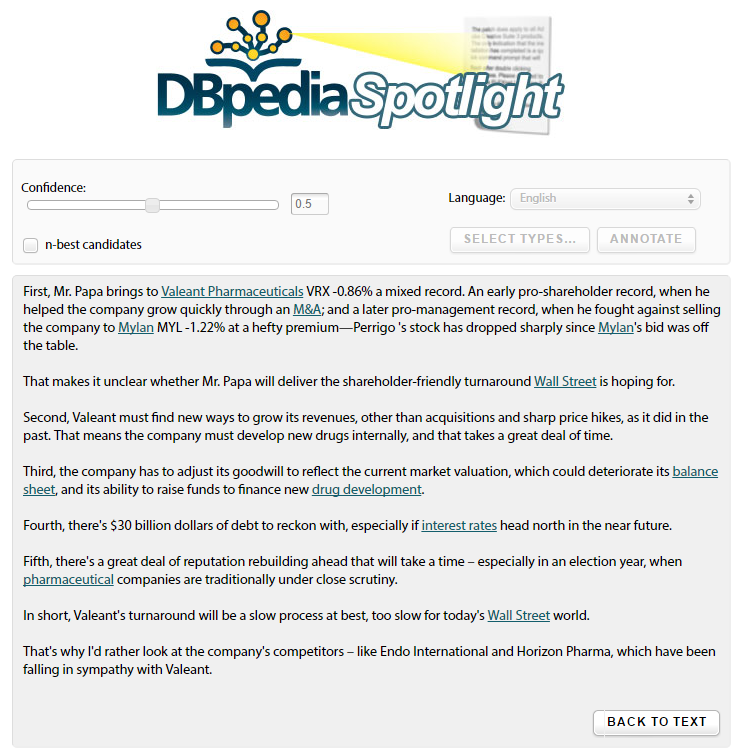
Yes, it gets the name of the main company (which was already tagged for this article,) and it gets the name of one other company. Yet, it's pretty vacuous that the company is involved in M&A, has a balance sheet, could be affected by interest rates, and is traded on Wall Street, despite those things being correctly identified. The use of concepts for, say, search indexing, adds very little real value here, particularly because it's failing to identify the names of 3 out 5 of the companies mentioned.
If we lower the confiedence score we get more results, but these are almost all noise or uninteresting (note that meaningful phrases such as "Endo International" or "Horizon Pharma"are split into two links, thus are not correctly recognized by the system)
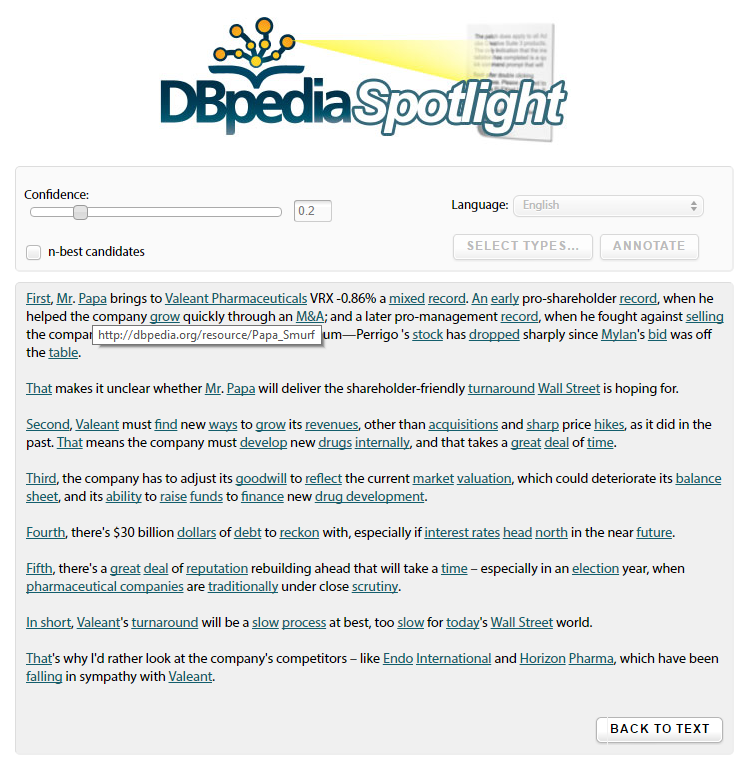
If you look at any of the other text analysis APIs that have been demonstrated or are on the market, such the Alchemy API which was bought by IBM (which now claims to be part of IBM Watson), it is the same story. At high confidence levels mistakes are infrequent, but few interesting terms are identified. At low confidence, the results are outright embarassing. Either way, once these results are entered in a data pipeline, errors tends to snowball, and you don't get any lift relative to old-fashioned "bag of words" methods.
If you did a quick evaluation of Spotlight or some similar product you'd notice that there are certain mistakes that come up over and over again; that has to do with the power nature of the world, that the most common errors occur much more often than others. If you had a human looking at documents you could point out mistakes quickly, but products like Spotlight, and especially it's commercial competitors, are provided on an "as is" basis, and you don't have any way to tune them at all. In the case of Spotlight, you could hire somebody to work for 6 months or so, assemble a training set with hundreds of thousands of cases. As is the case with speech recognition, they'll get results that are much better on paper, but might not be so good in real life because time is spent splitting the wrong hairs and not on the attributes necessary for a commercially useful product.
(For example, a huge amount of mental effort can get spent on evaluating various answers that are "sorta kinda" right. For instance, If you parsed "New York Fire Department" as "New York" and "Fire Department" that is right, and if it was some little fire department such as the "Brooktondale" "Volunteer Fire Department" that is not in your database, it is correct to split up the phrase. To express that it needs to resolve the NYFD as a specific entity but break down fire departments that aren't in the database is a large burden when you're having to apply it consistenly across the hundreds of thousands or millions of test cases that the currently fashionable machine learning systems require. Yet, since you can't measure something more accurately than the ruler you measure it, current approaches can make you spend a huge amount of effort not just determining right from wrong, but differentiating between various sorts of "more" and "less right" answers without a principled way to express that.)
It reminds of the quote, "The definition of insanity is doing the same thing over and over again and expecting a different result," which was written by mystery writer Rita Mae Brown (and misattributed to everyone from Albert Einstein to L. Ron Hubbard.) It is not good psychiatry, but it describes the feeling people have when a computer makes the same mistake over and over again and they have no way to correct it, other that create cumbersome and error-prone programs that require continuous maintaince. Machine learning has made huge strides in the past decades, but it can't get out of the laboratory until domain experts, if not end users, can instruct the system to avoid common errors by interacting with the system once.
Real Semantics addresses these problems as follows: